

티스토리 뷰
이 글은 Backend Development 101 시리즈의 첫 번째 글입니다.
회원가입은 잘 되는데 로그인은 가끔 실패하고, 주문은 접수됐는데 재고는 마이너스로 떨어지고, 배포 직후부터 API 지연이 급증하는 상황을 팀에서 한 번쯤 겪습니다. 화면은 멀쩡한데 서비스가 흔들릴 때 원인은 대부분 백엔드의 책임 경계가 흐려진 지점에서 시작됩니다. 이 글은 "백엔드가 데이터를 처리한다" 수준을 넘어, 운영에서 버티는 구조를 어떻게 이해해야 하는지에 집중합니다.
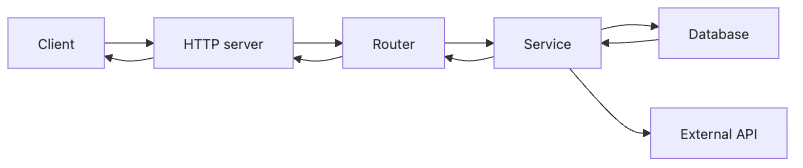
Backend Development 101 1장 흐름 개요
먼저 던지는 질문
- 백엔드는 정확히 어떤 역할과 경계를 가지는 계층일까요?
- 하나의 요청은 HTTP 서버, 라우터, 서비스, 데이터베이스를 어떻게 통과할까요?
- 왜 백엔드를 한 덩어리가 아니라 여러 레이어로 나눠 이해해야 할까요?
왜 백엔드가 운영 생존을 결정할까요?
백엔드는 단순한 "뒤쪽 코드"가 아닙니다. 사용자 요청을 신뢰 가능한 상태로 바꿔 주는 통제 계층입니다. 화면에서 클릭 한 번으로 발생한 이벤트가 결제, 재고, 알림, 로그, 권한 검사까지 연결될 때, 어느 단계에서 무엇을 검증하고 어떤 실패를 되돌릴지 판단하는 곳이 백엔드입니다.
초기 서비스는 기능 속도가 우선이라 라우트 함수에 모든 코드를 넣기 쉽습니다. 입장에서는 합리적입니다. 빠르게 동작하고 데모도 잘 나옵니다. 운영 트래픽이 붙는 순간 문제가 바뀝니다. 동시 요청이 늘어나고, 실패 재시도가 생기고, 외부 API 지연이 누적되면서 "가끔 실패"가 "항상 느림"으로 바뀝니다. 이때 필요한 것은 새 프레임워크가 아니라 책임을 분리한 구조입니다.
현업에서 자주 보이는 장애 문장을 구조 관점으로 바꾸면 다음과 같습니다. "왜 주문이 두 번 들어갔지?"는 중복 요청 제어가 없거나 트랜잭션 경계가 약한 문제입니다. "왜 관리자 권한이 일반 사용자에게 열렸지?"는 인가 검사를 서비스 밖에서 처리한 문제입니다. "왜 배포 후 특정 API만 500이 나지?"는 의존성 초기화와 예외 매핑이 레이어마다 다르게 흩어진 문제입니다.
다음 표는 "백엔드가 없다면"이 아니라 "백엔드 구조가 약하면" 실제로 어떤 운영 비용이 생기는지 보여줍니다.
| 상황 | 겉으로 보이는 증상 | 구조적 원인 | 운영 비용 |
|---|---|---|---|
| 피크 시간대 주문 폭주 | 응답 지연, 타임아웃 증가 | 비즈니스 로직과 DB 접근이 라우트에 혼재 | 원인 파악 지연, 임시 패치 반복 |
| 권한 버그 | 특정 사용자만 403/200 혼재 | 인가 정책이 여러 핸들러에 중복 | 회귀 버그 재발 |
| 배포 직후 장애 | 일부 API 500 | 초기화/설정 검증 위치 불명확 | 롤백 의존도 증가 |
| 데이터 불일치 | 재고 음수, 중복 결제 | 트랜잭션 경계와 멱등성 설계 부재 | 정산/고객 대응 비용 급증 |
핵심은 단순합니다. 백엔드는 기능 구현이 아니라 실패를 통제하는 설계입니다. 기능이 같은 코드 두 개가 있어도, 레이어 경계가 분명한 쪽이 운영에서 오래 버팁니다.
5계층 멘탈 모델: HTTP Server → Router → Middleware → Service → Repository/DB
요청 하나를 이해할 때 가장 실용적인 방법은 5계층으로 나눠 보는 것입니다. 이 모델은 특정 프레임워크 문법이 아니라 책임 경계를 고정하는 지도입니다. FastAPI로 예시를 들지만 Flask, Django, Node, Go에도 그대로 적용됩니다.
1) HTTP Server: 연결을 받고 프로세스로 전달하는 입구
HTTP Server는 소켓을 열고 요청/응답 규약을 처리합니다. FastAPI를 직접 실행하는 것처럼 보이지만 실제로는 Uvicorn 같은 ASGI 서버가 연결 수락, keep-alive, 타임아웃, 워커 모델을 담당합니다.
이 계층을 별도 관심사로 보는 이유는 애플리케이션 로직과 네트워크 로직의 실패 양상이 완전히 다르기 때문입니다. 비즈니스 코드는 정상인데 워커 수가 부족해서 큐가 밀릴 수 있습니다. 반대로 네트워크는 안정적인데 앱이 CPU를 점유해 응답이 느려질 수도 있습니다.
이 경계를 무시하면 "API가 느리다"를 전부 코드 탓으로만 보게 됩니다. 실제로는 --workers, 타임아웃, 이벤트 루프 정책 같은 런타임 설정 문제인데, 서비스 함수 최적화만 반복하다 시간을 잃습니다.
실무 시나리오: 배포 후 평균 응답이 3배 느려졌는데 코드 변경이 거의 없을 때, 원인은 Uvicorn 워커 수 기본값 유지와 CPU 코어 수 불일치였습니다. 서버 계층을 독립적으로 보지 않으면 이런 문제를 놓칩니다.
2) Router: URL을 유스케이스로 매핑하는 경계
Router는 경로와 HTTP 메서드를 해석해 어떤 핸들러가 실행될지 결정합니다. 여기의 역할은 "길 안내"입니다. 요청 파라미터 바인딩, 응답 스키마 연결, 버전 경로(/v1, /v2) 분리가 핵심입니다.
Router가 필요한 이유는 API 표면 계약을 집중 관리해야 하기 때문입니다. 같은 기능이라도 경로 규칙이 흐트러지면 클라이언트 호환성이 깨집니다. 라우터가 서비스 로직을 품기 시작하면 계약 변경과 정책 변경이 얽혀 배포 리스크가 커집니다.
이 계층을 건너뛰면 흔히 모든 엔드포인트가 하나의 파일에서 조건문으로 분기됩니다. 처음엔 단순해 보이지만 인증 정책이 늘고 버전이 늘면 "이 경로는 왜 404고 저 경로는 405인지"를 추적하기 어려워집니다.
실무 시나리오: 모바일 앱 구버전 지원 중 /users/me와 /me가 혼재되어 장애가 발생했습니다. 라우트 표면을 통합하지 않아 인가 미들웨어가 일부 경로에서만 동작했습니다.
3) Middleware: 모든 요청에 공통 규칙을 적용하는 관문
Middleware는 요청 전/후 공통 처리를 담당합니다. 예를 들면 요청 ID 생성, 인증 토큰 파싱, CORS, 로깅, 응답 시간 측정, 전역 예외 포맷팅이 여기에 속합니다.
분리 이유는 단순합니다. 공통 규칙을 핸들러마다 복사하면 일관성이 깨집니다. 인증 누락, 로그 포맷 불일치, 헤더 처리 누락이 발생합니다. 공통 책임은 한 번 정의하고 모든 경로에 동일하게 적용해야 운영 지표가 신뢰됩니다.
이 계층을 생략하면 "이 API는 로그가 있고 저 API는 없다" 같은 상태가 됩니다. 장애 대응 때 요청 추적이 끊깁니다. 특히 분산 환경에서는 X-Request-ID가 없으면 하나의 장애를 여러 건으로 오인합니다.
실무 시나리오: 결제 실패 건 조사에서 같은 주문 ID에 서로 다른 로그 ID가 찍혀 원인 분석이 6시간 지연됐습니다. 요청 ID 부여를 미들웨어로 중앙화하고 나서 재현과 추적 시간이 크게 줄었습니다.
4) Service: 비즈니스 규칙이 실제로 실행되는 계층
Service는 "무엇이 맞는 동작인가"를 코드로 표현합니다. 주문 가능 시간, 재고 차감 순서, 중복 결제 방지, 권한 정책 같은 규칙이 여기에 들어갑니다. Router는 전달만 하고, Service가 의사결정을 합니다.
Service를 분리하는 이유는 규칙의 수명이 가장 길기 때문입니다. 프레임워크, 데이터베이스, 배포 방식은 바뀌어도 비즈니스 규칙은 오래 남습니다. 테스트도 Service 단위에서 가장 큰 가치를 얻습니다.
Service가 없거나 약하면 핸들러마다 규칙이 복제됩니다. "같은 주문 생성인데 어떤 경로는 쿠폰 검사를 하고 어떤 경로는 안 한다" 같은 버그가 생깁니다. 코드 리뷰로는 발견이 늦고 운영에서 터집니다.
실무 시나리오: 관리자 API와 일반 API가 서로 다른 서비스 함수를 우회 호출해 재고 차감 순서가 달라졌고, 결국 재고 음수가 발생했습니다. Service를 단일 진입점으로 고치며 해결했습니다.
5) Repository/DB: 데이터 접근을 추상화하고 일관성 경계를 관리하는 계층
Repository는 SQL/ORM 쿼리, 커넥션 처리, 저장소별 접근 방식을 캡슐화합니다. DB는 영속성과 동시성 제어를 담당합니다. Service는 "무엇을 저장할지"를 말하고, Repository는 "어떻게 저장할지"를 실행합니다.
분리 이유는 저장소 교체와 테스트 용이성입니다. PostgreSQL을 쓰다가 읽기 전용 캐시를 붙이거나, 테스트에서 인메모리 저장소를 쓰려면 Repository 경계가 필요합니다. Service가 SQL 문자열을 직접 다루기 시작하면 변경 영향이 폭발합니다.
이 계층을 건너뛰면 트랜잭션 경계가 호출 지점마다 제각각이 됩니다. 같은 유스케이스가 어떤 경로에서는 원자적으로 처리되고, 다른 경로에서는 부분 반영됩니다.
실무 시나리오: 주문 생성 후 알림 발송을 같은 함수에서 처리하다 DB 커밋 전에 외부 API 실패가 나서 주문 상태 불일치가 발생했습니다. Repository 트랜잭션 경계를 명확히 하고 이벤트 아웃박스로 분리해 해결했습니다.
요청 라이프사이클: 한 건의 주문 요청을 5계층으로 추적하기
아래 코드는 POST /orders 요청이 각 계층을 어떻게 통과하는지 보여주는 축약 예시입니다.
from fastapi import FastAPI, APIRouter, Request, HTTPException
from pydantic import BaseModel
from typing import Dict
import time
import uuid
app = FastAPI()
router = APIRouter()
# Repository 계층
class OrderRepository:
def __init__(self):
self._store: Dict[str, dict] = {}
def save(self, order_id: str, user_id: str, item_id: str, quantity: int) -> dict:
data = {
"order_id": order_id,
"user_id": user_id,
"item_id": item_id,
"quantity": quantity,
"status": "created",
}
self._store[order_id] = data
return data
# Service 계층
class OrderService:
def __init__(self, repo: OrderRepository):
self.repo = repo
def create_order(self, user_id: str, item_id: str, quantity: int) -> dict:
# 비즈니스 규칙: 수량은 1 이상
if quantity < 1:
raise ValueError("quantity must be >= 1")
# 비즈니스 규칙: 여기에서 재고 확인, 결제 한도 검사 등이 추가됨
order_id = f"ord-{uuid.uuid4().hex[:8]}"
return self.repo.save(order_id, user_id, item_id, quantity)
repo = OrderRepository()
service = OrderService(repo)
# Middleware 계층
@app.middleware("http")
async def request_context_middleware(request: Request, call_next):
request_id = request.headers.get("x-request-id", uuid.uuid4().hex)
request.state.request_id = request_id
started = time.time()
response = await call_next(request)
elapsed_ms = int((time.time() - started) * 1000)
# 운영에서 추적 가능한 최소 정보
response.headers["x-request-id"] = request_id
response.headers["x-elapsed-ms"] = str(elapsed_ms)
return response
# Router 계층
class CreateOrderRequest(BaseModel):
user_id: str
item_id: str
quantity: int
@router.post("/orders")
def create_order(payload: CreateOrderRequest, request: Request):
try:
created = service.create_order(payload.user_id, payload.item_id, payload.quantity)
return {
"request_id": request.state.request_id,
"order": created,
}
except ValueError as exc:
raise HTTPException(status_code=400, detail=str(exc))
app.include_router(router)동작을 계층별로 해석하면 다음과 같습니다.
| 계층 | 코드에서 하는 일 | 이 위치에 둔 이유 |
|---|---|---|
| HTTP Server | Uvicorn이 소켓 수락, FastAPI 앱 호출 | 네트워크 처리와 비즈니스 로직 분리 |
| Router | @router.post("/orders")가 입력 스키마와 경로 연결 |
API 계약을 한곳에서 관리 |
| Middleware | x-request-id, x-elapsed-ms 부여 |
공통 관측성 정책 중앙화 |
| Service | 수량 검증, 주문 생성 규칙 | 유스케이스 정책을 재사용 가능하게 유지 |
| Repository/DB | save()로 영속화 |
저장소 구현 변경 영향 격리 |
여기서 중요한 지점은 "어디서 실패를 반환하느냐"입니다. 요청 형식 오류는 Router/Pydantic에서 422로 걸러집니다. 도메인 규칙 위반은 Service가 400으로 변환하도록 신호를 줍니다. DB 연결 실패는 Repository에서 발생하고 500 혹은 재시도 정책 대상으로 분류됩니다. 실패를 레이어마다 명확히 분류해야 알람과 대응 절차를 설계할 수 있습니다.
왜 레이어링이 실제로 이득일까요?
테스트 가능성: 한 레이어만 가짜로 바꿔 검증
레이어 분리의 첫 이득은 테스트입니다. Service 테스트에서 DB를 띄우지 않고 Repository를 가짜로 대체하면 규칙 검증 속도가 매우 빨라집니다.
class FakeOrderRepository:
def __init__(self):
self.saved = []
def save(self, order_id, user_id, item_id, quantity):
row = {
"order_id": order_id,
"user_id": user_id,
"item_id": item_id,
"quantity": quantity,
"status": "created",
}
self.saved.append(row)
return row
def test_create_order_rejects_invalid_quantity():
repo = FakeOrderRepository()
svc = OrderService(repo)
try:
svc.create_order("u1", "i1", 0)
assert False, "예외가 발생해야 합니다"
except ValueError:
assert len(repo.saved) == 0핵심은 "규칙 위반 시 저장이 일어나지 않는다"를 빠르게 증명하는 것입니다. 통합 테스트만으로 이 조건을 확인하면 느리고 원인 분리가 어렵습니다.
교체 가능성: 저장소 변경을 국소화
초기에는 SQLite 또는 단일 PostgreSQL로 시작해도 됩니다. 트래픽이 커지면 읽기 캐시, 샤딩, 메시지 큐 기반 비동기 처리가 필요해집니다. Repository 경계가 있으면 Service 코드는 거의 건드리지 않고 저장소 구현만 교체할 수 있습니다.
예를 들어 OrderRepository 인터페이스를 유지한 채 PostgresOrderRepository에서 DynamoOrderRepository로 바꿀 때, 호출부는 DI 설정만 수정하면 됩니다. 이 변경이 라우트와 비즈니스 규칙에 번지지 않으면 배포 위험이 크게 낮아집니다.
팀 경계: 책임 소유권을 명확히
팀이 2명일 때는 체감이 적지만 6명 이상이 되면 소유권이 중요합니다. API 계약은 플랫폼/백엔드 공통 소유, 도메인 규칙은 서비스 담당, 쿼리 최적화는 데이터 담당처럼 나누면 충돌이 줄어듭니다.
책임 경계가 없으면 같은 PR에서 경로 변경, 권한 정책 변경, 인덱스 변경이 동시에 일어납니다. 리뷰도 얕아지고 장애도 복합적으로 발생합니다. 레이어링은 아키텍처 취향이 아니라 팀 작업 단위를 안정화하는 장치입니다.
Before/After: 같은 기능을 단일 핸들러와 레이어드 구조로 비교
아래 두 코드는 모두 "주문 생성" 기능을 수행합니다. 기능은 같지만 운영 품질이 다릅니다.
Before: 단일 핸들러에 모든 책임 집중
@app.post("/orders")
def create_order(payload: dict):
# 입력 검증
if "user_id" not in payload or "item_id" not in payload:
return {"error": "invalid"}, 400
quantity = int(payload.get("quantity", 0))
if quantity < 1:
return {"error": "invalid quantity"}, 400
# 권한 검사(실제로는 외부 서비스 호출)
token = payload.get("token")
if token != "allow":
return {"error": "forbidden"}, 403
# 데이터 저장
conn = get_db_connection()
cur = conn.cursor()
cur.execute(
"INSERT INTO orders(user_id, item_id, quantity) VALUES (%s, %s, %s) RETURNING id",
(payload["user_id"], payload["item_id"], quantity),
)
order_id = cur.fetchone()[0]
conn.commit()
# 로깅
print("created", order_id)
# 외부 알림
send_webhook(order_id)
return {"order_id": order_id}, 201문제는 길이가 아니라 결합도입니다. 이 함수는 입력, 인가, 저장, 로깅, 외부 통신을 동시에 가집니다. send_webhook이 실패하면 재시도 전략이 불분명하고, DB 커밋과 알림 실패가 엇갈릴 때 일관성 정책도 없습니다. 테스트는 사실상 통합 테스트로만 가능해집니다.
After: 같은 기능을 레이어드로 분리
# router.py
@router.post("/orders", status_code=201)
def create_order(payload: CreateOrderRequest, request: Request):
result = order_service.create_order(
actor_token=request.headers.get("authorization"),
user_id=payload.user_id,
item_id=payload.item_id,
quantity=payload.quantity,
)
return result
# service.py
class OrderService:
def __init__(self, authz: AuthzClient, repo: OrderRepository, outbox: EventOutbox):
self.authz = authz
self.repo = repo
self.outbox = outbox
def create_order(self, actor_token: str, user_id: str, item_id: str, quantity: int) -> dict:
if quantity < 1:
raise DomainError("quantity must be >= 1")
if not self.authz.can_create_order(actor_token, user_id):
raise PermissionDenied("not allowed")
order = self.repo.create(user_id=user_id, item_id=item_id, quantity=quantity)
self.outbox.enqueue("order.created", {"order_id": order["id"]})
return order이 구조의 장점은 실패 지점이 명확하다는 것입니다. 인가 실패는 PermissionDenied, 규칙 위반은 DomainError, 영속화 실패는 Repository 예외로 구분됩니다. 관측성과 재시도 정책을 계층별로 설계할 수 있어 운영 대응이 빨라집니다.
실전 핸즈온: FastAPI로 5단계 구축하기
이 섹션은 빠른 튜토리얼이 아니라 "각 단계가 왜 필요한지"를 확인하는 목적입니다.
1단계: 최소 서버 기동으로 네트워크 경계를 분리
# app.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/health")
def health():
return {"status": "ok"}uvicorn app:app --reload --port 8000여기서 확인할 점은 애플리케이션 함수가 아니라 서버 경계입니다. 포트 바인딩, 프로세스 기동, 기본 헬스 응답이 안정적이어야 이후 계층이 의미를 가집니다.
2단계: Router 분리로 API 표면을 고정
# routes/orders.py
from fastapi import APIRouter
router = APIRouter(prefix="/orders", tags=["orders"])
@router.get("/")
def list_orders():
return []# app.py
from fastapi import FastAPI
from routes.orders import router as orders_router
app = FastAPI()
app.include_router(orders_router)경로 분리는 단순한 파일 정리가 아닙니다. 팀이 API 변경을 검토할 때 라우터 디렉터리를 보면 계약 변경 범위를 즉시 파악할 수 있습니다.
3단계: Middleware로 관측성 기본값 확보
# middlewares/request_id.py
import time
import uuid
from fastapi import Request
async def request_id_middleware(request: Request, call_next):
# 모든 요청에 추적 ID를 부여
request_id = request.headers.get("x-request-id", uuid.uuid4().hex)
request.state.request_id = request_id
started = time.time()
response = await call_next(request)
elapsed_ms = int((time.time() - started) * 1000)
response.headers["x-request-id"] = request_id
response.headers["x-elapsed-ms"] = str(elapsed_ms)
return response# app.py
app.middleware("http")(request_id_middleware)이 단계가 중요한 이유는 "나중에 로깅 붙이면 되지"가 운영에서 잘 통하지 않기 때문입니다. 장애 후 로그를 추가하면 원인 구간 데이터가 없습니다.
4단계: Service로 유스케이스 규칙을 모으기
# services/order_service.py
class OrderService:
def __init__(self, repo):
self.repo = repo
def create(self, user_id: str, item_id: str, quantity: int):
# 도메인 규칙: 최소 주문 수량
if quantity < 1:
raise ValueError("quantity must be >= 1")
return self.repo.create(user_id=user_id, item_id=item_id, quantity=quantity)규칙을 서비스로 모으면 재사용과 테스트가 쉬워집니다. 같은 규칙을 API, 배치, 메시지 컨슈머에서 공유할 수 있습니다.
5단계: Repository로 저장소 의존성을 고립
# repositories/order_repository.py
class OrderRepository:
def __init__(self, db):
self.db = db
def create(self, user_id: str, item_id: str, quantity: int):
# 저장소 구현 세부사항은 이 계층에 고립
row = self.db.execute(
"""
INSERT INTO orders(user_id, item_id, quantity)
VALUES (:user_id, :item_id, :quantity)
RETURNING id, user_id, item_id, quantity
""",
{"user_id": user_id, "item_id": item_id, "quantity": quantity},
).fetchone()
return dict(row)저장소를 고립하면 DB 교체뿐 아니라 트랜잭션 정책 변경도 국소화됩니다. 성능 이슈가 발생했을 때 쿼리 튜닝 범위를 좁힐 수 있습니다.
자주 하는 실수와 왜 문제가 커질까요?
| 실수 | 당장은 편한 이유 | 나중에 깨지는 지점 | 깨지는 이유 |
|---|---|---|---|
| 라우트에 모든 로직 작성 | 파일 하나만 보면 됨 | 기능 증가 시 변경 충돌 | 경계가 없어 테스트/리뷰 단위 붕괴 |
| 서버 재검증 생략 | 프론트에서 이미 검사함 | 악의적 요청/버전 불일치 | 클라이언트는 신뢰 경계 밖 |
| 예외를 전부 500으로 반환 | 처리 코드가 단순함 | 장애 분류 불가 | 사용자 오류와 시스템 오류 혼합 |
| DB 모델을 API 응답으로 직출력 | 변환 코드가 없음 | 스키마 변경 시 호환성 파손 | 내부 모델과 외부 계약 미분리 |
| 로그에 컨텍스트 누락 | 구현이 빠름 | 재현 불가 | 요청 ID, 사용자 ID, 경로 정보 부재 |
각 실수는 코드 스타일 문제가 아니라 운영 비용 문제입니다. 예를 들어 400과 500을 구분하지 않으면 알람이 과도하게 울리고, 팀은 실제 장애 신호를 놓칩니다. 응답 스키마를 분리하지 않으면 DB 마이그레이션 하나가 클라이언트 장애로 이어집니다.
"왜 이런 일이 생겼지?"를 구조적으로 해석하는 습관이 중요합니다. 장애는 보통 한 줄 버그보다 경계 부재에서 시작됩니다.
시니어 엔지니어는 어떻게 판단할까요?
시니어는 "어떤 프레임워크가 더 좋다"보다 "어떤 실패를 어디서 흡수할지"를 먼저 정합니다. 주문 생성 유스케이스를 본다면, 입력 검증 실패는 즉시 4xx로 종료하고, 외부 결제 실패는 재시도/보상 트랜잭션으로 분리하고, DB 일관성은 트랜잭션 경계 안에서 보장하도록 설계합니다. 기능 플로우보다 실패 플로우를 먼저 그립니다.
두 번째로, 경계를 코드 구조와 운영 지표에 동시에 반영합니다. 서비스 계층 메서드마다 도메인 이벤트를 정의하고, 미들웨어에서 요청 컨텍스트를 붙이고, 저장소 계층에서 쿼리 지연을 측정합니다. 이렇게 하면 "느리다"라는 제보가 들어왔을 때 레이어별 원인 후보를 즉시 줄일 수 있습니다.
세 번째로, 트레이드오프를 명시합니다. 모든 것을 완벽히 분리하면 초기 개발 속도가 떨어질 수 있습니다. 시니어는 그래서 "어떤 경계는 지금 고정하고, 어떤 경계는 나중에 분리할지"를 팀 상황에 맞춰 결정합니다. 예를 들어 MVP 단계에서는 단일 DB를 유지하되 Service/Repository 경계는 초기에 도입해 이후 확장 비용을 줄입니다. 목표는 이상적인 구조가 아니라 변화 비용을 예측 가능한 수준으로 유지하는 것입니다.
처음 질문으로 돌아가기
- 백엔드는 정확히 어떤 역할과 경계를 가지는 계층일까요?
백엔드는 요청을 받아 규칙을 적용하고, 데이터를 안전하게 변경하며, 실패를 분류해 응답으로 돌려주는 통제 계층입니다. 본문에서 본 5계층 모델처럼 HTTP 처리, 경로 계약, 공통 정책, 비즈니스 규칙, 저장소 접근을 분리해야 운영에서 원인을 빠르게 찾을 수 있습니다. - 하나의 요청은 HTTP 서버, 라우터, 서비스, 데이터베이스를 어떻게 통과할까요?
POST /orders예시에서 요청은 서버가 연결을 수락하고, 라우터가 핸들러를 선택하고, 미들웨어가 요청 ID/지연 시간을 부여한 뒤, 서비스가 규칙을 검증하고, 저장소가 영속화합니다. 실패도 레이어별로 다르게 나타나며 422, 400, 500을 구분해 처리해야 알람과 대응이 정확해집니다. - 왜 백엔드를 한 덩어리가 아니라 여러 레이어로 나눠 이해해야 할까요?
레이어 분리는 테스트에서 가짜 저장소를 사용해 규칙을 빠르게 검증하게 해 주고, 저장소 교체 시 변경 범위를 줄이며, 팀 소유권 충돌을 줄입니다. Before/After 비교처럼 기능은 같아도 레이어드 구조가 장애 분석 시간과 회귀 버그를 크게 줄여 줍니다.
시리즈 목차
- 백엔드 개발이란 무엇인가? (현재 글)
- HTTP 서버 만들기 (예정)
- Routing과 Controller (예정)
- Service Layer (예정)
- Database Layer (예정)
- 인증과 권한 (예정)
- Logging과 Error Handling (예정)
- 백엔드 테스트 (예정)
- 백엔드 배포 (예정)
- 운영 가능한 백엔드 구조 (예정)
참고 자료
공식 문서
'Software Engineering' 카테고리의 다른 글
| Backend Development 101 (3/10): Routing과 Controller (0) | 2026.05.21 |
|---|---|
| Backend Development 101 (2/10): HTTP 서버 만들기 (0) | 2026.05.21 |
| API Design 101 (10/10): 좋은 API 문서 만들기 (0) | 2026.05.20 |
| API Design 101 (9/10): Versioning (0) | 2026.05.20 |
| API Design 101 (8/10): OpenAPI와 Swagger (0) | 2026.05.20 |
- Total
- Today
- Yesterday
- http
- Computer Science
- softwaredesign
- DesignPatterns
- Cleancode
- langchain
- Prompt engineering
- AI Evaluation
- Production
- serverless
- APIDesign
- DevOps
- harness
- Architecture
- Cloud
- Tool Use
- ai safety
- Refactoring
- ai agent
- Azure Functions
- Python
- backend
- embeddings
- AZURE
- rag
- openAI
- vector search
- reliability
- LLM
- Agent
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |