

티스토리 뷰
이 글은 Backend Development 101 시리즈의 5번째 글입니다.
서비스 계층이 자라기 시작하면 데이터베이스 코드는 거의 항상 같은 증상으로 무너집니다. 목록 API는 처음에 빠르다가 어느 날 갑자기 10배 느려지고, 운영 배포 직후 특정 엔드포인트만 500을 내며, 로컬에서는 재현되지 않는 타임아웃이 반복됩니다. 원인을 따라가 보면 SQL 자체가 틀린 경우보다, 데이터 접근 책임이 흩어져 있고 스키마 변경 이력이 통제되지 않으며 세션 수명이 요청 경계를 벗어나 있는 경우가 더 많습니다.
데이터베이스 레이어의 목적은 단순히 ORM을 도입하는 일이 아닙니다. 도메인 변경 속도와 운영 안정성을 동시에 지키기 위해, 쿼리·트랜잭션·스키마 변경·성능 관찰 지점을 한 프레임 안에 묶는 일입니다. repository pattern은 그 프레임의 경계이고, ORM은 생산성을 높이는 도구이며, migration은 팀이 같은 데이터 구조를 공유하도록 만드는 버전 관리 체계입니다.
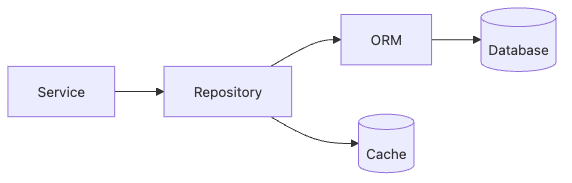
Backend Development 101 5장 흐름 개요
먼저 던지는 질문
- 왜 service가 SQL을 직접 작성하지 않는 편이 좋을까요?
- repository pattern은 어떤 경계를 만들어 줄까요?
- ORM은 왜 편리하면서도 함정을 함께 가져올까요?
Repository Pattern을 먼저 잡아야 하는 이유
repository는 "DB에 접근하는 코드 묶음"이 아닙니다. 서비스 계층이 도메인 언어로 말하도록 만들고, 데이터 접근 구현을 교체 가능한 어댑터로 제한하는 경계입니다. 이 경계가 있으면 성능 개선과 인프라 변경이 서비스 로직을 흔들지 않습니다.
1) 테스트 가능성: DB 없이 도메인 규칙을 검증할 수 있습니다
서비스가 SQLAlchemy Session이나 raw SQL을 직접 호출하면 단위 테스트가 통합 테스트로 밀려납니다. 테스트가 느려지고, 실패 원인이 비즈니스 규칙인지 DB 상태인지 분리하기 어려워집니다. repository 인터페이스를 두면 서비스는 fake repository로 검증하고, DB 연동 테스트는 별도 계층에서 집중할 수 있습니다.
from dataclasses import dataclass
from typing import Protocol
@dataclass
class User:
id: int | None
email: str
is_active: bool = True
class UserRepository(Protocol):
def find_by_email(self, email: str) -> User | None: ...
def save(self, user: User) -> User: ...
class UserService:
def __init__(self, users: UserRepository):
self.users = users
def register(self, email: str) -> User:
# 중복 이메일을 서비스 규칙으로 강제합니다.
if self.users.find_by_email(email):
raise ValueError("이미 가입된 이메일입니다")
return self.users.save(User(id=None, email=email))2) 쿼리 중앙화: 성능 이슈를 찾는 시간이 짧아집니다
쿼리가 컨트롤러, 서비스, 유틸 함수에 흩어져 있으면 슬로우 쿼리를 발견해도 소유 코드가 보이지 않습니다. repository에 쿼리 책임을 모으면 인덱스 튜닝, 로딩 전략 변경, 캐시 도입 지점이 명확해집니다. 운영에서 "어디를 고칠지"가 명확하다는 점이 가장 큰 비용 절감입니다.
3) 백엔드 교체 가능성: "영원히 PostgreSQL" 가정에서 벗어납니다
초기에는 PostgreSQL 단일 노드로 충분해도, 트래픽이 커지면 read replica, 검색 전용 저장소, 이벤트 소싱 보조 저장소가 붙습니다. repository 경계가 없으면 서비스 레이어가 특정 DB API에 잠기고 교체 비용이 폭증합니다. 경계가 있으면 구현만 단계적으로 교체할 수 있습니다.
Raw SQL vs ORM: 무엇이 더 낫다가 아니라 책임이 다릅니다
ORM 논쟁은 도구 선호 문제처럼 보이지만, 실제로는 "어떤 종류의 복잡성을 어디에 둘 것인가"의 선택입니다.
| 관점 | Raw SQL 중심 | ORM 중심 |
|---|---|---|
| 학습 곡선 | SQL 지식이 바로 필요, 진입 장벽 높음 | 모델 선언으로 빠른 생산성 확보 |
| 복잡 쿼리 제어 | 실행 계획/힌트/CTE 제어가 직접적 | 추상화가 이점을 주지만 복잡 쿼리는 우회 필요 |
| 유지보수 | SQL 문자열 중복과 매핑 코드 증가 위험 | 모델/세션 규칙 정리 시 일관성 확보 |
| 성능 디버깅 | 쿼리가 명시적이라 추적 용이 | lazy loading/N+1 같은 숨은 비용 주의 |
| 테스트 | DB 의존 강해지는 경향 | repository+ORM 조합으로 계층 분리 쉬움 |
| 팀 협업 | SQL 숙련도 편차 영향 큼 | 도메인 객체 중심 협업에 유리 |
언제 Raw SQL을 선택하는가
- 복잡한 분석 쿼리(윈도 함수, 재귀 CTE, DB 벤더 특화 기능) 비중이 높을 때
- ORM 생성 SQL이 비효율적이어서 실행 계획 통제가 핵심일 때
- 배치/리포팅처럼 읽기 전용 경로가 분리되어 있을 때
언제 ORM을 선택하는가
- CRUD와 관계 매핑이 API의 대부분을 차지할 때
- 도메인 모델 중심으로 서비스 규칙을 관리하고 싶을 때
- 마이그레이션 도구(Alembic)와 함께 스키마 진화를 표준화하려 할 때
실무 기본 전략
대부분의 팀은 "ORM 기본 + 병목 구간에 선택적 Raw SQL" 조합으로 갑니다. ORM을 버리는 게 아니라, 병목 쿼리만 명시적으로 드러내는 방식입니다.
SQLAlchemy 구성요소를 역할로 이해하기
SQLAlchemy를 처음 도입할 때 흔한 실수는 engine/session/model을 한 덩어리로 보는 것입니다. 세 요소는 역할이 다르고, 문제도 다른 층에서 발생합니다.
Engine: DB와 연결되는 저수준 관문
engine은 DB 드라이버와 연결 풀을 관리합니다. 애플리케이션이 매 요청마다 새 TCP 연결을 여는 대신 풀에서 재사용하게 만들며, 타임아웃/풀 크기/재시도 정책의 기준점이 됩니다.
from sqlalchemy import create_engine
engine = create_engine(
"postgresql+psycopg://app:secret@db:5432/app",
pool_size=20,
max_overflow=40,
pool_timeout=5,
pool_recycle=1800,
pool_pre_ping=True,
)pool_size: 기본 유지 연결 수max_overflow: 순간 증가 허용량pool_timeout: 풀에서 연결을 못 구할 때 대기 시간pool_pre_ping: 죽은 연결 재사용 방지
Session: 트랜잭션 경계를 표현하는 작업 단위
session은 "요청 단위 작업공간"입니다. 객체 변경을 추적하고 flush/commit/rollback 시점을 관리합니다. 세션 수명이 길어지면 connection leak와 lock 경합이 생기므로, 요청 경계 안에서 열고 닫는 패턴이 기본입니다.
from sqlalchemy.orm import sessionmaker
SessionLocal = sessionmaker(bind=engine, autoflush=False, expire_on_commit=False)
def get_session():
session = SessionLocal()
try:
yield session
session.commit()
except Exception:
# 실패 트랜잭션을 즉시 되돌립니다.
session.rollback()
raise
finally:
# 연결을 풀로 반환합니다.
session.close()Model 선언: 스키마와 도메인 경계의 접점
모델은 단순한 "테이블 클래스"가 아니라, 스키마 제약과 도메인 규칙의 최소 계약입니다. nullable, unique, index 여부를 모델에 명시하면 migration diff와 코드 리뷰 기준이 일관해집니다.
from datetime import datetime
from sqlalchemy import String, DateTime, func
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
class Base(DeclarativeBase):
pass
class UserModel(Base):
__tablename__ = "users"
id: Mapped[int] = mapped_column(primary_key=True)
email: Mapped[str] = mapped_column(String(255), unique=True, index=True)
name: Mapped[str] = mapped_column(String(100))
created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True), server_default=func.now())Alembic Migration: 스키마 변경을 코드처럼 다뤄야 하는 이유
"운영 DB에 ALTER TABLE 한 번"은 빠른 해결처럼 보이지만, 팀 관점에서는 재현 불가능한 상태를 만들기 시작한 신호입니다. 스키마는 애플리케이션과 같은 수준으로 버전 관리되어야 합니다.
왜 버전 관리가 필요한가
- 로컬/스테이징/운영 스키마 드리프트 방지
- 배포 롤백 시 데이터 구조 복원 경로 확보
- 코드 리뷰에서 스키마 영향 범위 사전 검토
- 장애 분석 시 "어느 릴리즈에서 구조가 바뀌었는지" 추적 가능
권장 워크플로우: autogenerate → review → apply
alembic revision --autogenerate -m "add user email index"
# 생성된 스크립트를 리뷰합니다.
alembic upgrade headautogenerate는 시작점이지 정답이 아닙니다. 제약조건 이름, 인덱스 생성 방식, nullable 전환의 데이터 백필 절차를 반드시 수동 검토해야 합니다.
"""add user email index
Revision ID: 20260521_add_email_index
Revises: 20260520_add_users
"""
from alembic import op
import sqlalchemy as sa
def upgrade() -> None:
# 운영 조회 경로에 필요한 인덱스를 명시적으로 추가합니다.
op.create_index("ix_users_email", "users", ["email"], unique=True)
def downgrade() -> None:
op.drop_index("ix_users_email", table_name="users")"배포 후 데이터 불일치" 시나리오
운영에서 코드만 배포되고 migration이 누락되면 앱은 새 컬럼을 기대하는데 DB는 옛 스키마를 유지합니다. 증상은 column does not exist, ORM 매핑 오류, 무음 데이터 손실로 나타납니다. 배포 파이프라인에 alembic upgrade head를 명시하고, 배포 전후 alembic current를 기록으로 남겨야 합니다.
트랜잭션 관리: 일관성을 지키는 최소 단위
트랜잭션 문제는 "실패 시 롤백"만으로 끝나지 않습니다. 세션 수명, flush 타이밍, 잠금 범위까지 함께 다뤄야 실제 장애를 줄일 수 있습니다.
요청 단위 세션 라이프사이클
- 요청 시작 시 세션 생성
- 서비스/리포지터리 작업 수행
- 성공 시 commit
- 예외 시 rollback
- 항상 close
이 흐름이 깨지는 대표 패턴은 "전역 세션 재사용"입니다. 특정 요청의 실패 상태가 다음 요청으로 전파되어 예측 불가능한 오류가 생깁니다.
commit/rollback 경계 설계
- 서비스 메서드가 도메인 작업 단위를 정의합니다.
- repository는 쿼리를 수행하되, 트랜잭션 종료 권한은 상위 계층이 갖습니다.
- 외부 API 호출과 DB commit을 같은 트랜잭션처럼 다루지 않습니다.
class OrderService:
def __init__(self, orders, payments):
self.orders = orders
self.payments = payments
def place_order(self, session, cmd):
order = self.orders.create(session, cmd)
try:
self.payments.charge(cmd.user_id, cmd.amount)
session.commit()
return order
except Exception:
session.rollback()
raise커넥션 풀 설정이 필요한 이유
동시 요청이 늘면 DB 병목보다 먼저 풀 고갈이 터집니다. 기본값에 기대면 트래픽 피크에서 QueuePool limit reached가 발생합니다. 애플리케이션 워커 수, DB max_connections, p95 쿼리 시간을 기준으로 풀 파라미터를 조정해야 합니다.
N+1 문제: 느린 목록 API의 가장 흔한 원인
N+1은 "목록 1회 조회 + 각 항목마다 추가 조회" 패턴입니다. 로컬 샘플 데이터에서는 티가 안 나지만, 운영 데이터 크기에서 지연이 폭발합니다.
느린 쿼리 로그에서 보이는 신호
- 같은 SQL 템플릿이 짧은 구간에 수십/수백 번 반복
SELECT ... WHERE id = ?형태가 요청 한 번에 연속 등장- API 로그는 한 번인데 DB 로그는 N+1 개
예시 로그:
[req-8f1] SELECT id, title FROM orders ORDER BY created_at DESC LIMIT 50;
[req-8f1] SELECT id, order_id, price FROM order_items WHERE order_id = 101;
[req-8f1] SELECT id, order_id, price FROM order_items WHERE order_id = 102;
...
[req-8f1] SELECT id, order_id, price FROM order_items WHERE order_id = 150;탐지 방법
- SQLAlchemy
echo또는 structured SQL logging 활성화 - APM(New Relic, Datadog)에서 요청당 쿼리 수 추적
- 슬로우 쿼리 로그에서 동일 패턴 집계
해결 전략: eager loading / subquery / join
| 전략 | 장점 | 주의점 | 추천 상황 |
|---|---|---|---|
selectinload (eager) |
부모 먼저, 자식 IN 조회로 N+1 완화 | IN 목록이 지나치게 길면 부담 | 일반적인 1:N 목록 API |
joinedload |
단일 조인으로 왕복 최소화 | row 중복으로 데이터량 증가 | 자식 수가 적고 즉시 렌더 필요 |
| subquery 기반 조회 | 쿼리 제어 유연 | ORM 추상화 이점 일부 감소 | 복잡 필터/정렬 동시 요구 |
from sqlalchemy import select
from sqlalchemy.orm import selectinload
stmt = (
select(OrderModel)
.options(selectinload(OrderModel.items))
.order_by(OrderModel.created_at.desc())
.limit(50)
)
orders = session.scalars(stmt).all()Connection Pool Exhaustion: "요청은 왔는데 DB 연결이 없다"
풀 고갈은 보통 세 가지 원인으로 발생합니다.
- 세션/커넥션을 닫지 않아 반환이 지연됨
- 긴 트랜잭션이 연결을 오래 점유함
- 워커/스레드 수 대비 풀 설정이 과소함
진단: 활성 커넥션을 먼저 확인합니다
PostgreSQL 기준으로 현재 연결 상태를 보면 누수가 빠르게 드러납니다.
SELECT
state,
count(*) AS cnt
FROM pg_stat_activity
WHERE datname = 'app'
GROUP BY state
ORDER BY cnt DESC;추가로 오래 열린 트랜잭션을 확인합니다.
SELECT
pid,
now() - xact_start AS tx_age,
state,
query
FROM pg_stat_activity
WHERE xact_start IS NOT NULL
ORDER BY tx_age DESC
LIMIT 20;수정 방향
- 요청 스코프 세션 강제(
try/finally close) - 장시간 배치 작업은 별도 워커/별도 풀 분리
- DB
max_connections와 앱 풀 합산 재계산 - 타임아웃 짧게 설정해 대기 폭주 차단
인덱싱 기초: 밀리초가 초 단위가 되는 경계
"로컬은 빠른데 운영은 느리다"의 절반은 인덱스 문제입니다. 로컬 데이터가 작으면 풀 스캔 비용이 숨겨지기 때문입니다.
언제 인덱스를 고려해야 하는가
- WHERE/JOIN/ORDER BY에 반복 등장하는 컬럼
- 높은 선택도(selectivity)를 가진 검색 키
- 페이지네이션 기준 컬럼(created_at, id)
EXPLAIN ANALYZE로 확인하는 습관
EXPLAIN ANALYZE
SELECT id, email
FROM users
WHERE email = 'alice@example.com';Seq Scan이 반복되고 실행 시간이 데이터 증가에 비례하면 인덱스 후보입니다. 인덱스 추가 후에는 실행 계획이 Index Scan 또는 Bitmap Index Scan으로 바뀌는지 확인합니다.
운영 시나리오 4가지로 보는 문제 해결
1) 로컬은 빠른데 운영만 느립니다
- 증상: 목록 API p95가 80ms → 1.8s
- 원인: 운영 DB에 누락된 복합 인덱스
- 확인:
EXPLAIN ANALYZE에서Seq Scan + Sort - 조치: migration으로 인덱스 추가, 배포 후 계획 재확인
2) 배포 후 데이터가 맞지 않습니다
- 증상: 새 코드가 특정 컬럼을 못 찾음
- 원인: migration 단계 스킵
- 확인:
alembic current와 기대 revision 불일치 - 조치: 배포 파이프라인에 migration 강제, 실패 시 앱 롤아웃 중단
3) 부하 시 풀 고갈이 발생합니다
- 증상:
QueuePool limit reached, API 타임아웃 연쇄 - 원인: 세션 미반환 + 긴 트랜잭션
- 확인:
pg_stat_activity에서 idle in transaction 다수 - 조치: 세션 수명 단축, 트랜잭션 분할, 풀/워커 균형 조정
4) 목록 API가 갑자기 10배 느려졌습니다
- 증상: 요청당 쿼리 수 급증
- 원인: lazy loading으로 N+1 발생
- 확인: 동일 자식 조회 SQL 반복
- 조치:
selectinload또는joinedload적용, 요청당 쿼리 수 회귀 테스트 추가
DB 테스트 전략: 속도와 신뢰도를 같이 가져가기
테스트에서는 "빠른 피드백"과 "실제 DB 동작 검증"을 분리해야 합니다.
SQLite 단독 전략의 한계
SQLite는 빠르지만 PostgreSQL과 타입/락/인덱스 동작이 다릅니다. SQLite 테스트만 통과해도 운영에서 깨질 수 있습니다.
권장 조합
- 단위 테스트: fake repository로 서비스 규칙 검증
- 통합 테스트: Testcontainers(PostgreSQL)로 실제 쿼리/트랜잭션 검증
- 격리 전략: 테스트마다 rollback 또는 schema recreate
import pytest
from sqlalchemy.orm import Session
@pytest.fixture
def db_session(engine):
conn = engine.connect()
tx = conn.begin()
session = Session(bind=conn)
try:
yield session
finally:
session.close()
# 테스트가 남긴 데이터를 롤백으로 즉시 정리합니다.
tx.rollback()
conn.close()자주 하는 실수와 시니어 관점의 교정
- 서비스 레이어에서 즉석 SQL 작성
- 왜 문제인가: 도메인 규칙과 데이터 접근이 결합되어 변경 비용이 커집니다.
- 시니어 판단: 쿼리 소유권을 repository로 명시하고 리뷰 기준을 분리합니다.
- "ORM이 알아서 최적화"라는 기대
- 왜 문제인가: 로딩 전략 기본값은 성능 의도를 담지 않습니다.
- 시니어 판단: 핵심 엔드포인트는 요청당 쿼리 수와 p95를 같이 관리합니다.
- 마이그레이션 자동 생성본을 무검토 적용
- 왜 문제인가: 제약조건/인덱스/데이터 백필 누락이 운영 장애로 이어집니다.
- 시니어 판단: autogenerate는 초안, 최종본은 수동 리뷰라는 팀 규칙을 둡니다.
- 세션 생명주기 방치
- 왜 문제인가: 커넥션 누수와 lock 경합은 트래픽 피크에서만 폭발합니다.
- 시니어 판단: 프레임워크 레벨 dependency로 open/close를 강제합니다.
- 인덱스 없는 기능 배포
- 왜 문제인가: 기능 테스트는 통과해도 데이터 규모가 커지면 즉시 병목이 됩니다.
- 시니어 판단: 새 조회 경로는 PR 단계에서
EXPLAIN캡처를 요구합니다.
실무 체크리스트
- 서비스는 repository 인터페이스에만 의존합니다.
- 요청 스코프 세션/트랜잭션 경계가 코드로 강제됩니다.
- migration 생성 후 수동 리뷰 절차가 있습니다.
- 핵심 목록 API는 N+1 회귀 테스트가 있습니다.
- 운영 DB에서 슬로우 쿼리 로그와 활성 커넥션 모니터링이 켜져 있습니다.
- 신규 조회 API는 인덱스와 실행 계획 검토를 포함합니다.
마무리
데이터베이스 레이어의 품질은 "쿼리가 동작하느냐"가 아니라 "변경과 운영에서 예측 가능하냐"로 결정됩니다. repository pattern은 책임 경계를 고정하고, ORM은 생산성을 끌어올리며, migration은 팀 전체의 스키마 상태를 동기화합니다. 여기에 트랜잭션 수명 관리, N+1 탐지, 풀 고갈 대응, 인덱스 검증이 결합되어야 실제 운영에서 흔들리지 않습니다.
처음 질문으로 돌아가기
- 왜 service가 SQL을 직접 작성하지 않는 편이 좋을까요?
- 테스트 가능성과 쿼리 소유권을 분리하기 위해서입니다. 서비스는 도메인 규칙에 집중하고, 쿼리 최적화·인덱스 조정·저장소 교체는 repository 내부에서 통제할 때 변경 비용이 가장 낮아집니다.
- repository pattern은 어떤 경계를 만들어 줄까요?
- 서비스가 "무엇을 조회/저장할지"를 말하고 repository가 "어떻게 조회/저장할지"를 책임지는 경계를 만듭니다. 이 경계가 있어야 read replica 도입, 캐시 추가, raw SQL 최적화를 서비스 수정 없이 진행할 수 있습니다.
- ORM은 왜 편리하면서도 함정을 함께 가져올까요?
- 모델 중심 개발과 생산성을 주는 대신, 로딩 전략을 의식하지 않으면 N+1과 과도한 쿼리를 숨깁니다. ORM은 자동 최적화 도구가 아니라 명시적 로딩 정책과 로그 관찰을 전제로 쓸 때 효과적인 추상화입니다.
시리즈 목차
- Backend Development 101 (1/10): 백엔드 개발이란 무엇인가?
- Backend Development 101 (2/10): HTTP 서버 만들기
- Backend Development 101 (3/10): Routing과 Controller
- Backend Development 101 (4/10): Service Layer
- Database Layer (현재 글)
- 인증과 권한 (예정)
- Logging과 Error Handling (예정)
- 백엔드 테스트 (예정)
- 백엔드 배포 (예정)
- 운영 가능한 백엔드 구조 (예정)
참고 자료
공식 문서
추가 읽을거리
'Software Engineering' 카테고리의 다른 글
| Backend Development 101 (7/10): Logging과 Error Handling (2) | 2026.05.21 |
|---|---|
| Backend Development 101 (6/10): 인증과 권한 (0) | 2026.05.21 |
| Backend Development 101 (4/10): Service Layer (0) | 2026.05.21 |
| Backend Development 101 (3/10): Routing과 Controller (0) | 2026.05.21 |
| Backend Development 101 (2/10): HTTP 서버 만들기 (0) | 2026.05.21 |
- Total
- Today
- Yesterday
- serverless
- Cleancode
- LLM
- Azure Functions
- Python
- embeddings
- Prompt engineering
- DesignPatterns
- harness
- langchain
- AZURE
- Architecture
- reliability
- APIDesign
- Computer Science
- ai safety
- Refactoring
- Cloud
- vector search
- rag
- AI Evaluation
- ai agent
- DevOps
- http
- Production
- openAI
- Agent
- Tool Use
- backend
- softwaredesign
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |