

티스토리 뷰
컨테이너를 처음 다룰 때는 docker run 몇 번으로도 충분해 보입니다. 앱 하나, 데이터베이스 하나, 프록시 하나 정도라면 사람이 직접 상태를 맞춰도 큰 문제 없이 굴러갑니다. 하지만 서비스가 커지고 컨테이너 수가 늘어나면 상황이 달라집니다. 어느 서버에 무엇이 떠 있는지, 죽은 컨테이너를 누가 다시 띄우는지, 버전 교체를 어떻게 안전하게 할지부터 사람이 기억하고 맞추기 어려워집니다.
이 글은 Kubernetes 101 시리즈의 첫 번째 글입니다.
여기서는 Kubernetes를 단순히 "컨테이너를 많이 돌리는 도구"가 아니라, 원하는 상태를 선언하면 시스템이 그 상태로 계속 수렴하도록 만드는 오케스트레이터라는 관점에서 정리하겠습니다.
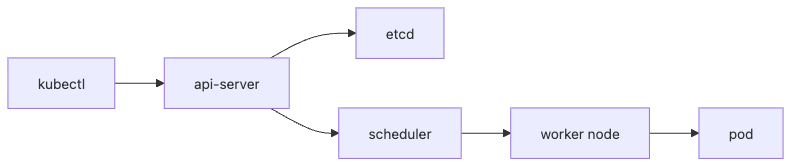
Kubernetes 101 1장 흐름 개요
Kubernetes는 '컨테이너를 많이 돌리는 도구'가 아니라 원하는 상태(desired state)를 선언하면 시스템이 그 상태로 계속 수렴하도록 만드는 오케스트레이터입니다 — 사람이 명령형으로 맞추던 일을 컨트롤러 루프에 위임한다는 한 가지 발상이 모든 리소스 설계의 출발점입니다.
먼저 던지는 질문
- 오케스트레이션이라는 말은 실제로 무엇을 대신해 줄까요?
- 컨트롤 플레인과 워커 노드는 어떤 식으로 역할을 나눌까요?
- 원하는 상태 모델이 왜 Kubernetes의 핵심 철학일까요?
왜 중요한가
컨테이너 몇 개는 Docker Compose만으로도 충분합니다. 하지만 수십 개가 넘어가면 누가 어떤 컨테이너를 어디에 배치할지, 장애가 나면 어떻게 복구할지, 새 버전으로 어떻게 교체할지 같은 문제가 한꺼번에 밀려옵니다. 이때부터는 컨테이너 런타임보다 오케스트레이터가 더 중요해집니다.
Kubernetes를 배우는 이유도 여기 있습니다. 많은 입문자가 Kubernetes를 "컨테이너 플랫폼" 정도로 받아들이지만, 실제로는 사람이 반복하던 운영 결정을 시스템 규칙으로 옮기는 도구에 가깝습니다. 이 관점을 먼저 잡아 두면 뒤에서 나오는 Pod, Deployment, Service도 훨씬 자연스럽게 이어집니다.
한눈에 보는 구조
이 그림을 볼 때 가장 먼저 기억할 점은 kubectl이 직접 컨테이너를 띄우지 않는다는 사실입니다. 사용자는 kubectl로 원하는 상태를 API 서버에 전달하고, 이후의 배치와 조정은 컨트롤 플레인 구성요소가 맡습니다. Kubernetes를 이해하려면 이 제어 흐름부터 알아야 합니다.
핵심 용어
- 클러스터: 컨트롤 플레인과 워커 노드를 묶은 전체 실행 환경입니다.
- 컨트롤 플레인: API 서버, etcd, scheduler, controller-manager처럼 클러스터의 제어를 맡는 영역입니다.
- 노드: 실제로 컨테이너가 실행되는 머신입니다.
- 원하는 상태: YAML에 선언한 목표 상태입니다.
kubectl: 클러스터 API와 통신하는 CLI입니다.
도입 전과 후
Kubernetes가 없을 때는 서버마다 수동으로 docker run을 실행하고, 죽은 컨테이너가 있으면 사람이 다시 올립니다. 같은 환경을 다른 서버에 재현하기도 쉽지 않습니다.
Kubernetes를 도입하면 상황이 달라집니다. 원하는 상태를 YAML로 선언하면 같은 구성을 다른 환경에 반복해서 적용할 수 있고, 시스템이 현재 상태를 계속 목표 상태에 맞추려 합니다. 재현성과 자동 복구가 여기서 시작됩니다.
단계별로 첫 클러스터 둘러보기
1단계 — 현재 컨텍스트 확인
import subprocess
def current_context():
res = subprocess.run(
["kubectl", "config", "current-context"],
capture_output=True, text=True, check=True,
)
return res.stdout.strip()가장 먼저 볼 값은 현재 컨텍스트입니다. kubectl은 단일 클러스터 전용 도구가 아니므로, 지금 어떤 클러스터를 바라보는지부터 확인해야 합니다. 입문 단계에서도 이 습관이 중요합니다.
2단계 — 노드 목록 확인
def get_nodes():
res = subprocess.run(
["kubectl", "get", "nodes", "-o", "wide"],
capture_output=True, text=True, check=True,
)
return res.stdout노드 목록은 이 클러스터가 실제로 어떤 실행 자원을 갖고 있는지 보여 줍니다. Kubernetes가 논리적인 제어 시스템처럼 보여도, 결국 워크로드는 워커 노드 위에서 돌아갑니다.
3단계 — 네임스페이스 확인
def list_namespaces():
res = subprocess.run(
["kubectl", "get", "ns"],
capture_output=True, text=True, check=True,
)
return res.stdout네임스페이스는 Kubernetes에서 가장 기본적인 격리 단위입니다. 워크로드를 그냥 한곳에 모두 넣는 대신, 환경이나 팀 단위로 나눠 운영하기 시작하는 출발점이라고 보면 됩니다.
4단계 — 시스템 파드 보기
def system_pods():
res = subprocess.run(
["kubectl", "-n", "kube-system", "get", "pods"],
capture_output=True, text=True, check=True,
)
return res.stdoutkube-system 네임스페이스를 보면 클러스터가 스스로를 운영하기 위해 어떤 구성요소를 띄우는지 감이 옵니다. Kubernetes는 단일 바이너리 하나가 아니라 여러 컴포넌트가 함께 움직이는 시스템이라는 점이 여기서 드러납니다.
5단계 — 클러스터 상태 확인
def cluster_info():
res = subprocess.run(
["kubectl", "cluster-info"],
capture_output=True, text=True, check=True,
)
return res.stdoutcluster-info는 클러스터 접근 경로를 빠르게 확인할 때 유용합니다. 처음에는 단순 조회처럼 보이지만, 실제 운영에서는 API 서버 접근 문제를 확인하는 첫 단계가 되기도 합니다.
검증 흐름
kubectl config current-context
kubectl get nodes -o wide
kubectl cluster-info예상되는 결과: 현재 컨텍스트 이름이 먼저 보이고, 이어서 노드 목록과 API 서버 엔드포인트가 정상적으로 출력돼야 합니다. 최소한 Ready 상태 노드 한 개 이상과 접근 가능한 control plane 주소를 확인할 수 있어야 합니다.
먼저 의심할 실패 모드:
current-context가 예상한 클러스터가 아니면 잘못된 kubeconfig를 보고 있을 가능성이 큽니다.kubectl get nodes가 timeout 나면 인증 정보보다 네트워크 경로나 API 서버 가용성을 먼저 확인하는 편이 빠릅니다.cluster-info는 되는데 노드가NotReady면 Kubernetes 개념 문제가 아니라 클러스터 상태 문제입니다.
이 코드에서 먼저 봐야 할 점
kubectl은 API 서버와 통신합니다.etcd를 직접 만지는 흐름은 일반적인 운영 경로가 아닙니다.- 네임스페이스가 기본 격리 단위라는 감각을 일찍 익히는 편이 좋습니다.
이 세 가지를 먼저 잡아 두면 Kubernetes를 "명령을 내리면 즉시 컨테이너가 뜨는 도구"로 오해하지 않게 됩니다. 사용자가 하는 일은 대부분 선언이고, 실제 조정은 컨트롤 플레인이 맡습니다.
자주 하는 실수 다섯 가지
- Kubernetes를 단순히 컨테이너와 같은 뜻으로 받아들입니다.
- 노드 수만 늘리면 운영 문제가 자동으로 해결된다고 생각합니다.
etcd를 일반 데이터 저장소처럼 직접 다루려 합니다.kubectl컨텍스트를 확인하지 않고 잘못된 클러스터에 적용합니다.- 워크로드 규모가 아주 작은데도 Kubernetes부터 도입합니다.
실무에서는 이렇게 봅니다
실무에서는 EKS, GKE, AKS 같은 관리형 Kubernetes를 기본 선택지로 두는 경우가 많습니다. 이유는 단순합니다. 팀이 직접 운영하고 싶은 것은 대개 애플리케이션이지, 컨트롤 플레인 자체가 아니기 때문입니다.
시니어 엔지니어는 Kubernetes를 볼 때 기능 목록보다 멘탈 모델을 먼저 봅니다. 원하는 상태를 선언하는 도구인지, 현재 상태를 그쪽으로 계속 밀어 붙이는 제어 시스템인지, 그리고 그 제어를 사람이 어디까지 직접 맡아야 하는지부터 구분합니다. 이 관점이 있어야 뒤에서 Deployment와 HPA를 볼 때도 흐름이 이어집니다.
체크리스트
- 적용 전 현재 컨텍스트를 확인했는가
- 워크로드를 네임스페이스로 나눌 계획이 있는가
- 원하는 상태를 YAML로 관리할 준비가 되었는가
- 관리형 Kubernetes를 먼저 검토했는가
연습 문제
- 컨트롤 플레인의 역할을 한 줄로 설명해 보세요.
- 원하는 상태가 왜 Kubernetes의 핵심인지 한 줄로 적어 보세요.
- Kubernetes 도입을 미루는 편이 나은 상황을 하나 떠올려 보세요.
마무리와 다음 글
이 글에서는 Kubernetes를 컨테이너 실행 도구가 아니라 원하는 상태를 유지하는 오케스트레이터로 보는 기본 관점을 잡았습니다. 컨트롤 플레인, 워커 노드, kubectl, 네임스페이스 같은 용어도 결국 이 모델 안에서 이해해야 서로 연결됩니다.
다음 글에서는 이 전체 시스템이 실제로 다루는 가장 작은 배포 단위인 Pod를 보겠습니다. Kubernetes의 많은 추상화는 결국 Pod를 중심으로 쌓여 있습니다.
매니페스트 중심 운영 예시
Kubernetes의 강점은 명령형 조작보다 선언형 매니페스트에 있습니다. 아래 예시는 Deployment, Service, Ingress를 분리해 책임 경계를 명확히 둔 기본 형태입니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: api
labels:
app: api
spec:
replicas: 3
selector:
matchLabels:
app: api
template:
metadata:
labels:
app: api
spec:
containers:
- name: api
image: ghcr.io/example/api:1.2.0
ports:
- containerPort: 8000
readinessProbe:
httpGet:
path: /healthz
port: 8000
initialDelaySeconds: 5
periodSeconds: 10
resources:
requests:
cpu: "200m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
---
apiVersion: v1
kind: Service
metadata:
name: api
spec:
selector:
app: api
ports:
- port: 80
targetPort: 8000
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: api
spec:
ingressClassName: nginx
rules:
- host: api.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: api
port:
number: 80readiness probe와 resource request/limit를 함께 정의하면 "배포는 되었지만 트래픽을 받으면 무너지는" 상태를 줄일 수 있습니다. 선언형 파일에서 운영 안정성을 미리 포함시키는 방식이 중요합니다.
kubectl 운영 명령 모음
매니페스트를 적용한 뒤에는 상태 관찰 명령을 빠르게 순환해야 합니다. 아래 조합은 장애 분석에서 가장 자주 사용하는 기본 세트입니다.
kubectl apply -f k8s/
kubectl get deploy,rs,pod -n prod -o wide
kubectl rollout status deploy/api -n prod
kubectl describe pod -n prod -l app=api
kubectl logs -n prod deploy/api --tail=200
kubectl get events -n prod --sort-by=.metadata.creationTimestamprollout status와 describe를 먼저 보면 이미지 pull 실패, probe 실패, 스케줄링 실패를 빠르게 구분할 수 있습니다. 로그만 먼저 보면 인프라 원인을 애플리케이션 오류로 오판하기 쉽습니다.
아키텍처 관점에서 봐야 할 경계
- API Server 경계: 모든 선언 변경은 API 서버를 통과합니다. 직접 노드에 접속해 상태를 손으로 맞추는 방식은 drift를 만듭니다.
- Scheduler 경계: Pod 배치는 자원 요청, taint/toleration, affinity 규칙의 결과입니다. 노드 선택 문제는 애플리케이션 버그와 분리해 봐야 합니다.
- Controller 경계: Deployment Controller는 replica 수렴과 롤링 업데이트를 담당합니다. desired/current 값 차이를 관찰하는 습관이 핵심입니다.
- Network 경계: Service와 Ingress는 L4/L7 책임이 다릅니다. 내부 통신 실패와 외부 진입 실패를 분리해 진단해야 대응이 빨라집니다.
이 경계를 기준으로 장애를 분해하면 "클러스터 문제"라는 모호한 결론 대신, 어느 계층에서 어떤 신호가 깨졌는지 명확히 남길 수 있습니다.
배포 안정성을 높이는 실무 체크
- 모든 워크로드에 readiness/liveness probe를 설정합니다.
latest태그 대신 고정 버전 태그를 사용해 롤백 기준을 확보합니다.- 변경 전
kubectl diff -f로 영향을 검토해 무의식적 설정 누락을 줄입니다. - 운영 네임스페이스에는 ResourceQuota와 LimitRange를 적용해 폭주 범위를 제한합니다.
- 배포 후
kubectl rollout history를 확인해 복구 경로를 문서화합니다.
Kubernetes는 기능이 많아서 어려운 도구가 아니라, 경계를 나누어 관찰하지 않으면 쉽게 혼란스러워지는 도구입니다. 매니페스트, 관찰 명령, 아키텍처 경계를 함께 묶어 운영하면 학습 속도와 안정성이 동시에 올라갑니다.
실전 아키텍처 리허설
개념을 이해했다면, 바로 작은 리허설을 해 보는 편이 좋습니다. 예를 들어 prod 네임스페이스에 API 하나를 배포하고, Service로 내부 노출한 뒤 Ingress로 외부 진입을 붙이는 흐름을 15분 안에 재현해 보세요. 핵심은 기능 구현이 아니라 경계 확인입니다. 어떤 변경이 API 서버에 기록되고, 어떤 변화가 컨트롤러를 통해 실제 파드 상태로 반영되는지 눈으로 확인해야 합니다.
kubectl create ns prod
kubectl apply -n prod -f k8s/api-deploy.yaml
kubectl apply -n prod -f k8s/api-svc.yaml
kubectl apply -n prod -f k8s/api-ing.yaml
kubectl get deploy,po,svc,ing -n prod -o wide이 과정을 할 때는 성공 여부보다 "어느 계층에서 상태가 바뀌었는가"를 기록하는 것이 중요합니다. 배포 직후에는 Deployment의 desired/current/available 값을 먼저 보고, 그다음 Pod 이벤트에서 pull, scheduling, probe 신호를 확인하세요. 이렇게 순서를 고정하면 팀 내 진단 언어가 통일됩니다.
문제 해결 워크플로: 신호를 계층별로 분해하기
운영에서 가장 많이 나오는 질문은 "서비스가 느립니다"처럼 모호합니다. 이 문장을 곧바로 애플리케이션 문제로 연결하지 말고, 계층별로 쪼개야 합니다.
- 진입 계층: Ingress Controller 로그와 4xx/5xx 비율
- 서비스 계층: Endpoints에 healthy Pod가 연결되는지
- 워크로드 계층: Pod 재시작 횟수, probe 실패, OOMKilled
- 클러스터 계층: 노드 압박(memory/disk/pressure), eviction
kubectl get endpoints api -n prod -o yaml
kubectl describe deploy api -n prod
kubectl get pod -n prod -l app=api -o wide
kubectl top pod -n prod
kubectl top node이 순서를 문서화해 두면, 온콜 인수인계 품질이 크게 올라갑니다. Kubernetes는 기능보다 운영 루틴이 품질을 만듭니다.
리소스 기준선과 변경 관리
입문 단계에서도 리소스 기준선을 꼭 잡아 두세요. requests는 스케줄링 약속이고, limits는 과다 사용 방지선입니다. 둘을 비워 둔 채 운영을 시작하면, 특정 파드의 순간 폭주가 노드 전체 불안정으로 번질 수 있습니다.
resources:
requests:
cpu: "250m"
memory: "256Mi"
limits:
cpu: "750m"
memory: "768Mi"변경은 kubectl apply만 하지 말고 kubectl diff를 기본 루틴으로 넣으세요. 변경 전 차이를 확인하면 의도하지 않은 필드 삭제, 레이블 불일치, probe 누락을 초기에 잡을 수 있습니다.
운영 시뮬레이션 확장
클러스터 전체 관점의 문서를 읽고 끝내면 실제 운영에서 금방 잊힙니다. 그래서 학습 직후에 "장애를 일부러 만들어 보고 복구하는" 시뮬레이션을 반드시 권장합니다. 여기서 중요한 점은 성공 데모를 반복하는 것이 아니라, 실패 신호를 표준 절차로 읽는 훈련을 하는 것입니다. 팀이 성장할수록 기술 격차보다 절차 격차가 더 큰 장애를 만듭니다.
먼저 시뮬레이션 전 공통 기준을 맞춥니다. 대상 네임스페이스를 분리하고, 적용한 매니페스트의 Git SHA를 기록하고, 관찰 명령 5개를 고정합니다. 이 기준이 있어야 "누가, 어떤 상태에서, 무엇을 바꿨는지"를 추적할 수 있습니다.
kubectl config current-context
kubectl get ns
kubectl get deploy,po,svc,ing -n prod -o wide
kubectl get events -n prod --sort-by=.metadata.creationTimestamp
kubectl top pod -n prod다음으로 장애 주입 시나리오를 단계적으로 실행합니다. 첫째, 잘못된 이미지 태그를 넣어 ImagePullBackOff를 발생시킵니다. 둘째, readiness probe 경로를 의도적으로 틀려 Ready 전환 실패를 만듭니다. 셋째, 메모리 limit를 과도하게 낮춰 OOM 재시작을 유도합니다. 넷째, selector 불일치를 만들어 트래픽 블랙홀을 재현합니다. 이 네 가지는 초급 팀이 실제 운영에서 가장 자주 만나는 장애 패턴입니다.
kubectl set image deploy/api api=ghcr.io/example/api:not-found -n prod
kubectl rollout status deploy/api -n prod
kubectl describe pod -n prod -l app=api
kubectl logs -n prod deploy/api --previous
kubectl rollout undo deploy/api -n prod복구 절차는 항상 동일한 순서를 사용합니다. 1) 영향 범위 확인, 2) 즉시 완화(rollback/scale), 3) 원인 확인, 4) 재발 방지 반영입니다. 순서를 바꾸면 현장에서 토론만 길어지고 복구는 늦어집니다. 특히 온콜 시간대에는 "정확한 분석"보다 "안전한 복구"를 먼저 해야 합니다.
운영 품질을 높이려면 기술 항목을 문서 항목으로 바꿔야 합니다. 예를 들어 "probe를 잘 설정한다"가 아니라 "모든 워크로드는 readiness/liveness를 필수로 포함하고, 경로는 헬스 라우터 표준(/readyz, /livez)을 사용한다"처럼 검증 가능한 규칙으로 적어야 합니다. 또 "리소스를 적절히 준다" 대신 "CPU request는 최근 7일 P50의 1.3배, memory limit는 P99의 1.2배" 같은 팀 기준선을 고정하면 논쟁 비용이 줄어듭니다.
런북에 남겨야 할 최소 항목
- 장애 유형별 최초 확인 명령 3개
- 즉시 완화 명령과 금지 명령
- 롤백 기준 버전과 검증 체크리스트
- 관련 대시보드 링크와 알림 임계치
- 동일 유형 재발 시 담당 팀 에스컬레이션 경로
문서를 이 수준으로 남기면 신규 팀원이 들어와도 대응 품질이 유지됩니다. Kubernetes 운영 성숙도는 기능 사용량이 아니라 "동일 장애를 같은 속도로 복구할 수 있는가"로 측정하는 편이 정확합니다.
실무 검증 체크포인트
운영에서 변경을 배포할 때는 코드 리뷰와 별도로 클러스터 검증 체크를 둬야 합니다. 체크 항목은 복잡할 필요가 없습니다. 적용 전 kubectl diff, 적용 후 rollout status, 엔드포인트 연결 확인, 로그 샘플 확인, 자원 사용률 확인 정도만 일관되게 수행해도 대다수 실수를 초기에 차단할 수 있습니다.
kubectl diff -f k8s/ -n prod
kubectl apply -f k8s/ -n prod
kubectl rollout status deploy/api -n prod
kubectl get endpoints api -n prod
kubectl top pod -n prod -l app=api여기서 마지막으로 중요한 원칙은 "수동 핫픽스를 원복 가능한 상태로 남긴다"는 점입니다. 긴급 대응 중에 kubectl edit로 해결했다면, 근무 종료 전에 반드시 매니페스트에 같은 변경을 반영해 drift를 없애야 합니다. 선언형 시스템에서 drift는 시간이 지날수록 큰 장애로 돌아옵니다.
관측성과 보안 기본선
Kubernetes 학습이 진행될수록 기능 사용량은 늘어나지만, 실제 장애를 줄이는 요소는 관측성과 보안 기본선입니다. 최소한 애플리케이션 로그, 인프라 이벤트, 자원 메트릭이 같은 시간축에서 비교 가능해야 하고, 서비스 계정 권한과 시크릿 접근 범위가 분리되어 있어야 합니다. 이 두 축이 약하면 배포 속도가 빨라질수록 실패 속도도 같이 빨라집니다.
관측성 기본선은 거창할 필요가 없습니다. 워크로드마다 공통 레이블(app, component, version)을 강제하고, 로그에 요청 식별자와 에러 코드를 남기고, 대시보드에서 레이블 필터로 바로 분해할 수 있으면 됩니다. 이벤트 스트림까지 함께 보면 "배포 변경"과 "오류 급증"의 시간적 상관관계를 빠르게 확인할 수 있습니다.
kubectl get events -n prod --sort-by=.metadata.creationTimestamp
kubectl logs -n prod deploy/api --since=10m
kubectl top pod -n prod -l app=api
kubectl top node보안 기본선에서는 RBAC 최소 권한 원칙을 먼저 적용하세요. 운영 계정이 모든 네임스페이스에 쓰기 권한을 가지면 단기적으로는 편하지만, 실수 한 번이 전체 서비스로 번질 수 있습니다. 네임스페이스 단위 Role/RoleBinding을 기본으로 두고, 클러스터 전역 권한은 예외 승인 절차를 거치도록 설계하는 편이 안전합니다.
또한 NetworkPolicy를 도입하면 "통신이 되는 것이 기본"인 상태를 "허용한 통신만 된다"는 상태로 바꿀 수 있습니다. 초기에는 DNS, 내부 API, 데이터베이스 같은 필수 경로부터 열고, 나머지는 점진적으로 차단하는 방식이 현실적입니다. 정책은 기능이 아니라 운영 안전장치입니다.
마지막으로, 변경 후 검증을 자동화하세요. kubectl apply 이후에 상태 확인 명령을 사람이 매번 동일하게 수행하기 어렵기 때문에, CI에서 kubectl diff, kubeconform류 스키마 체크, 서버 사이드 dry-run을 묶어 두면 기본 결함을 배포 전에 차단할 수 있습니다. Kubernetes 운영 성숙도는 고급 기능보다 "기본 검증을 빠짐없이 반복하는 능력"에서 먼저 올라갑니다.
처음 질문으로 돌아가기
- 오케스트레이션이라는 말은 실제로 무엇을 대신해 줄까요?
- 사람이 서버마다
docker run을 반복하고 죽은 컨테이너를 직접 다시 띄우던 작업, 즉 배치·재시작·버전 교체 같은 운영 결정을 시스템 규칙으로 옮기는 일이 오케스트레이션의 실체입니다. 본문에서는 같은 구성을 YAML로 선언만 하면 다른 서버에서도 그대로 재현된다는 점을 도입 전후 비교로 보였습니다.
- 사람이 서버마다
- 컨트롤 플레인과 워커 노드는 어떤 식으로 역할을 나눌까요?
- 컨트롤 플레인은 API 서버, etcd, scheduler, controller-manager로 구성되어 "어디에 무엇을 띄울지" 결정을 맡고, 워커 노드는 그 결정에 따라 실제 컨테이너를 실행합니다.
kubectl이 컨테이너를 직접 띄우지 않고 API 서버에 원하는 상태만 전달한다는 점에서 이 분리가 가장 잘 드러납니다.
- 컨트롤 플레인은 API 서버, etcd, scheduler, controller-manager로 구성되어 "어디에 무엇을 띄울지" 결정을 맡고, 워커 노드는 그 결정에 따라 실제 컨테이너를 실행합니다.
- 원하는 상태 모델이 왜 Kubernetes의 핵심 철학일까요?
- 사용자는 목표 상태를 YAML로 선언하고 컨트롤러가 현재 상태를 그 목표에 계속 수렴시키기 때문에, 자동 복구와 재현성이 부수적 기능이 아니라 기본 동작으로 주어집니다. 본문의 Deployment·Service·Ingress 예시처럼 desired/current 차이를 관찰하는 습관이 운영의 시작점이 되는 이유도 여기 있습니다.
시리즈 목차
- Kubernetes란 무엇인가? (현재 글)
- Pod (예정)
- Deployment (예정)
- Service (예정)
- Ingress (예정)
- ConfigMap과 Secret (예정)
- Volume (예정)
- HPA (예정)
- Helm (예정)
- 운영 관점의 Kubernetes (예정)
참고 자료
'Software Engineering' 카테고리의 다른 글
| Kubernetes 101 (3/10): Deployment (0) | 2026.06.02 |
|---|---|
| Kubernetes 101 (2/10): Pod (0) | 2026.06.02 |
| Docker 101 (10/10): 배포용 Docker 구성 (0) | 2026.06.01 |
| Docker 101 (9/10): Image 최적화 (0) | 2026.06.01 |
| Docker 101 (8/10): 데이터베이스와 함께 실행하기 (0) | 2026.06.01 |
- Total
- Today
- Yesterday
- langchain
- reliability
- softwaredesign
- backend
- containers
- http
- Computer Science
- Python
- AI Evaluation
- webdevelopment
- Production
- rag
- APIDesign
- Agent
- DevOps
- DesignPatterns
- AZURE
- LLM
- Cloud
- Tool Use
- Kubernetes
- frontend
- testing
- docker
- QUALITY
- openAI
- embeddings
- vector search
- Architecture
- ai agent
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |