
티스토리 뷰
클라우드 스토리지는 전부 비슷해 보이지만, 실제로는 접근 패턴과 내구성, 비용 구조에 따라 완전히 다른 서비스로 나뉩니다. S3, EBS, EFS, Glacier가 따로 존재하는 이유도 여기에 있습니다.
이 글은 Cloud Computing 101 시리즈의 5번째 글입니다.
저장소를 잘못 고르면 비용이 늘고 성능이 흔들리며 복구 전략까지 취약해집니다. 반대로 처음에 맞는 저장소를 고르면 오랫동안 큰 수정 없이 안정적으로 운영할 수 있습니다.
여기서는 객체, 블록, 파일, 아카이브 스토리지를 어떤 기준으로 구분해야 하는지 봅니다.
Cloud Computing 101 5장 흐름 개요
스토리지 선택은 데이터의 구조, 접근 패턴, 내구성 요구사항을 함께 고려하는 결정입니다.
먼저 던지는 질문
- 객체, 블록, 파일, 아카이브 스토리지는 각각 무엇이 다를까요?
- 내구성과 가용성은 왜 같은 말이 아닐까요?
- S3 라이프사이클 정책은 어떤 문제를 해결할까요?
왜 중요한가
모든 데이터를 VM 디스크에 몰아넣는 방식은 처음에는 단순해 보여도 백업, 확장, 복구에서 빠르게 한계를 드러냅니다. 반대로 데이터의 성격에 맞춰 저장 계층을 분리하면 비용과 운영 모두 훨씬 예측 가능해집니다.
예를 들어 로그는 S3에 쌓아 두었다가 시간이 지나면 Glacier로 내리는 편이 합리적입니다. 데이터베이스 볼륨은 블록 스토리지가 적합하고, 여러 인스턴스가 공유해야 하는 디렉터리는 파일 스토리지가 맞습니다. 저장소는 "어디든 넣으면 되는 공간"이 아니라 워크로드 구조의 일부입니다.
한눈에 보는 개념
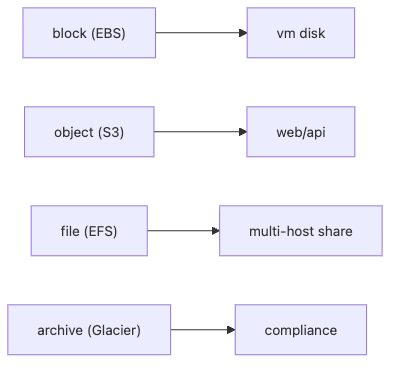
블록 스토리지는 디스크처럼, 객체 스토리지는 키-값 저장소처럼, 파일 스토리지는 공유 디렉터리처럼 동작합니다. 아카이브는 거의 읽지 않지만 오래 보관해야 하는 데이터를 위한 계층입니다.
핵심 용어
- Object: 메타데이터를 가진 키-값 객체 저장 방식입니다.
- Block: 고정 블록 단위의 디스크형 저장소입니다.
- File: POSIX 스타일 디렉터리 구조를 가진 파일시스템입니다.
- Durability: 데이터가 살아남을 확률입니다.
- Lifecycle: 시간이 지나면서 저장 계층을 전환하는 정책입니다.
적용 전후 비교
Before에서는 모든 파일이 VM 디스크에 놓여 백업과 복구가 악몽이 됩니다.
After에서는 객체는 S3에 저장하고, 오래된 데이터는 Glacier로 넘기는 정책을 둡니다.
이렇게 계층을 나누면 저장 비용뿐 아니라 복구 전략도 훨씬 명확해집니다.
실습: S3 객체 라이프사이클
1단계 — 클라이언트
import boto3
s3 = boto3.client("s3")2단계 — 객체 업로드
def put(bucket, key, body):
s3.put_object(Bucket=bucket, Key=key, Body=body)
return f"s3://{bucket}/{key}"3단계 — 객체 조회
def get(bucket, key):
res = s3.get_object(Bucket=bucket, Key=key)
return res["Body"].read()4단계 — 라이프사이클 정책
policy = {
"Rules": [{
"ID": "to-glacier-after-90d",
"Status": "Enabled",
"Filter": {"Prefix": "logs/"},
"Transitions": [{"Days": 90, "StorageClass": "GLACIER"}],
}]
}5단계 — 적용
def apply_lifecycle(bucket, policy):
s3.put_bucket_lifecycle_configuration(
Bucket=bucket, LifecycleConfiguration=policy,
)이 예제는 저장소 비용 최적화가 나중의 정리 작업이 아니라, 처음부터 정책으로 설계할 수 있는 영역이라는 점을 보여 줍니다. 데이터를 얼마나 오래 둘지, 언제 더 싼 계층으로 내릴지 미리 정해 두면 운영이 훨씬 단순해집니다.
이 코드에서 먼저 봐야 할 점
- Prefix를 기준으로 객체 묶음에 같은 정책을 적용할 수 있습니다.
- Transition 규칙이 실제 비용 절감의 핵심입니다.
- EBS는 보통 한 시점에 하나의 VM에 연결합니다.
이 예제를 실제로 검증하는 순서
라이프사이클 정책은 만들어 두는 것보다 실제로 버킷에 적용되었는지 확인하는 과정이 더 중요합니다. 정책이 저장되지 않았거나 Prefix가 잘못 잡혀 있으면 비용 최적화는 문서에만 남고 실제 데이터는 계속 비싼 계층에 머뭅니다.
aws s3api get-bucket-lifecycle-configuration --bucket my-test-bucket-2026Expected output:
to-glacier-after-90d같은 Rule ID가 출력되어야 합니다.logs/Prefix와GLACIER전환 규칙이 함께 보여야 합니다.- 이 확인이 있어야 비용 절감 정책이 실제 저장소에 반영되었다고 말할 수 있습니다.
자주 막히는 지점
- S3 버킷 정책과 라이프사이클 정책은 목적이 다릅니다. 하나는 접근 제어이고, 다른 하나는 보관 계층 관리입니다.
- Glacier는 값이 싸지만 즉시 읽기에는 적합하지 않습니다. 복원 시간까지 운영 계획에 넣어야 합니다.
- EFS를 공유 파일시스템으로 쓰면서도 EBS 같은 지연 시간 특성을 기대하면 구조가 어긋납니다.
내구성과 가용성은 왜 다를까
내구성은 데이터가 장기적으로 살아남는 가능성에 가깝고, 가용성은 지금 당장 읽고 쓸 수 있는가에 더 가깝습니다. 입문 단계에서는 이 둘을 같은 말처럼 쓰기 쉽지만, 실무에서는 분리해서 봐야 합니다.
예를 들어 아카이브 계층은 내구성이 매우 높아도 즉시 읽기에는 적합하지 않을 수 있습니다. 반대로 빠르게 접근 가능한 스토리지가 항상 가장 싸거나 가장 오래 보관하기 좋은 것은 아닙니다. 저장소 선택은 결국 접근 패턴을 기준으로 해야 합니다.
자주 하는 실수 5가지
- 공개 ACL로 S3 버킷을 노출합니다.
- 라이프사이클 정책을 만들지 않아 비용이 계속 누적됩니다.
- EBS 스냅샷을 남기지 않습니다.
- EFS를 고성능 IOPS 스토리지처럼 기대합니다.
- Glacier 복원 시간을 고려하지 않습니다.
실무에서는 이렇게 생각합니다
- 접근 패턴이 저장소를 결정합니다.
- 암호화는 선택 기능이 아니라 기본값입니다.
- 라이프사이클 정책은 첫날부터 정의하는 편이 좋습니다.
- 복원 비용과 시간도 총비용의 일부입니다.
- 백업과 복제는 같은 개념이 아닙니다.
체크리스트
- 기본 암호화를 활성화했는가.
- 라이프사이클 정책을 정의했는가.
- 공개 접근 차단이 기본값으로 설정되어 있는가.
- 연 1회 이상 복원 테스트를 수행하는가.
연습 문제
- Glacier의 복원 속도 계층 세 가지를 적어 보세요.
- S3 버전 관리를 켜 둘 만한 현실적인 시나리오 하나를 설명해 보세요.
- EBS와 EFS의 공유 방식 차이를 한 문장으로 정리해 보세요.
정리 및 다음 단계
데이터가 어디에 놓일지 정했다면, 이제는 그 데이터에 어떻게 연결하고 어떤 경로로 접근을 통제할지 살펴봐야 합니다. 다음 글에서는 Cloud 네트워킹의 기본인 Network로 넘어가겠습니다.
스토리지 선택 기준 상세표
| 유형 | 대표 서비스 | 지연 특성 | 확장 방식 | 적합 워크로드 |
|---|---|---|---|---|
| Block | EBS | 낮음 | 볼륨 단위 확장 | DB, 트랜잭션 로그 |
| Object | S3 | 중간 | 거의 무제한 | 이미지, 백업, 로그 |
| File | EFS | 중간 | 공유 파일시스템 | 다중 인스턴스 공유 디렉터리 |
| Archive | Glacier | 높음 | 장기 보관 | 규제 보관, 장기 백업 |
| 질문 | Block | Object | File | Archive |
|---|---|---|---|---|
| 랜덤 I/O 성능이 중요한가 | 적합 | 부적합 | 보통 | 부적합 |
| HTTP로 직접 접근해야 하는가 | 부적합 | 적합 | 부적합 | 부적합 |
| 여러 서버가 동시 쓰기하는가 | 제한적 | 제한적 | 적합 | 부적합 |
storage_lifecycle:
logs:
hot_days: 30
warm_class: STANDARD_IA
archive_after_days: 90
delete_after_days: 365
uploads:
versioning: true
replication: cross_regionEBS 볼륨 타입 비교
EBS는 단일 볼륨 타입이 아니라, 워크로드 특성에 따라 네 가지 계열로 나뉩니다. 선택을 잘못하면 IOPS 부족으로 DB가 느려지거나, 불필요한 프로비저닝으로 비용이 낭비됩니다.
| 볼륨 타입 | 최대 IOPS | 최대 처리량 | 지연 시간 | 적합 워크로드 |
|---|---|---|---|---|
| gp3 | 16,000 | 1,000 MB/s | 한 자릿수 ms | 범용 — 웹 서버, 개발 환경, 소규모 DB |
| io2 Block Express | 256,000 | 4,000 MB/s | sub-ms | 고성능 DB — Oracle, SAP HANA, 대규모 OLTP |
| st1 | 500 | 500 MB/s | 중간 | 순차 읽기 — 로그 분석, 데이터 레이크 ETL |
| sc1 | 250 | 250 MB/s | 높음 | 콜드 데이터 — 아카이브, 비활성 파일 서버 |
gp3는 기본 3,000 IOPS와 125 MB/s를 포함하므로 대부분의 워크로드에서 gp2보다 비용 효율이 좋습니다. io2는 IOPS를 볼륨 크기와 독립적으로 프로비저닝할 수 있어서, 작은 볼륨에 높은 IOPS가 필요한 DB에 적합합니다. st1과 sc1은 부트 볼륨으로 사용할 수 없다는 점도 기억해야 합니다.
S3 스토리지 클래스 비용 비교
S3 비용은 저장 단가만으로 판단하면 안 됩니다. 조회 비용, 최소 보관 기간, 복원 시간이 총비용에 큰 영향을 줍니다.
| 스토리지 클래스 | 저장 비용 (GB/월, us-east-1) | GET 요청 (1,000건) | 최소 보관 기간 | 복원 시간 |
|---|---|---|---|---|
| Standard | $0.023 | $0.0004 | 없음 | 즉시 |
| Standard-IA | $0.0125 | $0.001 | 30일 | 즉시 |
| One Zone-IA | $0.01 | $0.001 | 30일 | 즉시 |
| Glacier Instant Retrieval | $0.004 | $0.01 | 90일 | 즉시 |
| Glacier Flexible Retrieval | $0.0036 | $0.0004 + 복원비 | 90일 | 분~시간 |
| Glacier Deep Archive | $0.00099 | $0.0004 + 복원비 | 180일 | 12~48시간 |
저장 단가가 낮을수록 조회 비용이 높아지는 구조입니다. 따라서 접근 빈도가 높은 데이터를 Glacier에 넣으면 오히려 총비용이 올라갑니다. Intelligent-Tiering은 접근 패턴을 예측하기 어려울 때 자동으로 계층을 이동시켜 주지만, 모니터링 비용(객체당 월 $0.0025)이 추가됩니다.
S3 버킷 비용 분석기
아래 스크립트는 버킷의 현재 저장 비용과 라이프사이클 정책 적용 후 예상 비용을 비교합니다.
import boto3
from datetime import datetime, timezone
s3 = boto3.client("s3")
cw = boto3.client("cloudwatch")
PRICE_PER_GB = {
"STANDARD": 0.023,
"STANDARD_IA": 0.0125,
"ONEZONE_IA": 0.01,
"GLACIER": 0.0036,
"DEEP_ARCHIVE": 0.00099,
}
def get_bucket_size_by_class(bucket: str) -> dict[str, float]:
"""CloudWatch에서 스토리지 클래스별 버킷 크기를 조회합니다."""
result = {}
for storage_class in PRICE_PER_GB:
response = cw.get_metric_statistics(
Namespace="AWS/S3",
MetricName="BucketSizeBytes",
Dimensions=[
{"Name": "BucketName", "Value": bucket},
{"Name": "StorageType", "Value": storage_class},
],
StartTime=datetime.now(timezone.utc).replace(hour=0, minute=0),
EndTime=datetime.now(timezone.utc),
Period=86400,
Statistics=["Average"],
)
points = response.get("Datapoints", [])
if points:
result[storage_class] = points[0]["Average"] / (1024**3)
return result
def estimate_monthly_cost(size_by_class: dict[str, float]) -> float:
"""현재 스토리지 클래스 분포 기준 월 비용을 계산합니다."""
total = 0.0
for cls, gb in size_by_class.items():
total += gb * PRICE_PER_GB.get(cls, 0.023)
return total
def estimate_optimized_cost(
size_by_class: dict[str, float],
ia_ratio: float = 0.4,
glacier_ratio: float = 0.3,
) -> float:
"""라이프사이클 적용 후 예상 비용을 산출합니다."""
total_gb = sum(size_by_class.values())
standard_gb = total_gb * (1 - ia_ratio - glacier_ratio)
ia_gb = total_gb * ia_ratio
glacier_gb = total_gb * glacier_ratio
return (
standard_gb * PRICE_PER_GB["STANDARD"]
+ ia_gb * PRICE_PER_GB["STANDARD_IA"]
+ glacier_gb * PRICE_PER_GB["GLACIER"]
)
if __name__ == "__main__":
bucket_name = "my-app-prod"
sizes = get_bucket_size_by_class(bucket_name)
current = estimate_monthly_cost(sizes)
optimized = estimate_optimized_cost(sizes)
saving = current - optimized
print(f"현재 월 비용: ${current:.2f}")
print(f"최적화 후 예상: ${optimized:.2f}")
print(f"절감 가능 금액: ${saving:.2f} ({saving/current*100:.1f}%)")이 스크립트의 핵심은 "얼마나 절약할 수 있는가"를 숫자로 보여 주는 것입니다. 비용 최적화 제안을 팀에 전달할 때 감이 아닌 수치로 근거를 만들 수 있습니다.
Cross-Region Replication 설정
재해 복구나 규제 요건으로 데이터를 다른 리전에 복제해야 할 때 S3 Cross-Region Replication(CRR)을 사용합니다. 버전 관리가 켜져 있어야 하고, IAM 역할이 대상 버킷에 쓸 수 있는 권한을 가져야 합니다.
# 1. 소스/대상 버킷 모두 버전 관리 활성화
aws s3api put-bucket-versioning \
--bucket my-app-prod-us-east-1 \
--versioning-configuration Status=Enabled
aws s3api put-bucket-versioning \
--bucket my-app-prod-ap-northeast-2 \
--versioning-configuration Status=Enabled
# 2. 복제 규칙 적용
aws s3api put-bucket-replication \
--bucket my-app-prod-us-east-1 \
--replication-configuration '{
"Role": "arn:aws:iam::123456789012:role/S3ReplicationRole",
"Rules": [{
"ID": "replicate-all",
"Status": "Enabled",
"Priority": 1,
"Filter": {},
"Destination": {
"Bucket": "arn:aws:s3:::my-app-prod-ap-northeast-2",
"StorageClass": "STANDARD_IA"
},
"DeleteMarkerReplication": {"Status": "Enabled"}
}]
}'
# 3. 복제 상태 확인
aws s3api head-object \
--bucket my-app-prod-us-east-1 \
--key uploads/test.txt \
--query ReplicationStatus대상 버킷의 스토리지 클래스를 STANDARD_IA로 지정하면 복제본 저장 비용을 줄일 수 있습니다. 복제는 비동기로 동작하며, 대부분의 객체는 15분 이내에 대상 리전에 도달합니다.
백업 및 복구 전략: RTO/RPO 비교
스토리지 유형마다 백업 메커니즘과 복구 특성이 다릅니다. 서비스 수준 목표(SLA)에 맞는 전략을 선택해야 합니다.
| 스토리지 | 백업 방식 | RPO (목표 복구 시점) | RTO (목표 복구 시간) | 비고 |
|---|---|---|---|---|
| EBS | 스냅샷 (증분) | 스냅샷 주기에 의존 (1시간~1일) | 분 단위 (스냅샷에서 복원) | DLM으로 자동화 가능 |
| S3 | 버전 관리 + CRR | 거의 0 (버전 즉시 생성) | 즉시 (이전 버전 접근) | 삭제 마커 복원 주의 |
| EFS | AWS Backup | 백업 주기에 의존 | 수십 분~수 시간 | 파일 단위 복원 가능 |
| Glacier | Vault Lock + CRR | 해당 없음 (아카이브 자체가 백업) | 12~48시간 | 규제 보관용 |
RPO가 0에 가까워야 하면 S3 버전 관리나 동기식 복제를 씁니다. RTO가 짧아야 하면 EBS 스냅샷을 자주 생성하고 복원 절차를 자동화합니다. Glacier는 백업 대상이라기보다 장기 보관 자체가 목적인 계층입니다.
EBS 스냅샷 자동화
수동 스냅샷은 잊기 쉽습니다. 아래 스크립트는 특정 태그가 붙은 EBS 볼륨을 찾아 스냅샷을 생성하고, 오래된 스냅샷을 정리합니다.
import boto3
from datetime import datetime, timezone, timedelta
ec2 = boto3.client("ec2")
RETENTION_DAYS = 14
def create_snapshots(tag_key: str = "Backup", tag_value: str = "true"):
"""태그 기준으로 EBS 볼륨을 찾아 스냅샷을 생성합니다."""
volumes = ec2.describe_volumes(
Filters=[{"Name": f"tag:{tag_key}", "Values": [tag_value]}]
)
created = []
for vol in volumes["Volumes"]:
vol_id = vol["VolumeId"]
snap = ec2.create_snapshot(
VolumeId=vol_id,
Description=f"auto-{vol_id}-{datetime.now(timezone.utc):%Y%m%d}",
TagSpecifications=[{
"ResourceType": "snapshot",
"Tags": [
{"Key": "AutoBackup", "Value": "true"},
{"Key": "VolumeId", "Value": vol_id},
],
}],
)
created.append(snap["SnapshotId"])
return created
def cleanup_old_snapshots():
"""보관 기간이 지난 자동 스냅샷을 삭제합니다."""
cutoff = datetime.now(timezone.utc) - timedelta(days=RETENTION_DAYS)
snapshots = ec2.describe_snapshots(
Filters=[{"Name": "tag:AutoBackup", "Values": ["true"]}],
OwnerIds=["self"],
)
deleted = []
for snap in snapshots["Snapshots"]:
if snap["StartTime"] < cutoff:
ec2.delete_snapshot(SnapshotId=snap["SnapshotId"])
deleted.append(snap["SnapshotId"])
return deleted
if __name__ == "__main__":
new_snaps = create_snapshots()
print(f"생성된 스냅샷: {len(new_snaps)}개")
old_snaps = cleanup_old_snapshots()
print(f"삭제된 스냅샷: {len(old_snaps)}개")이 스크립트를 Lambda + EventBridge 스케줄(매일 UTC 03:00 등)로 연결하면 운영자가 개입하지 않아도 스냅샷이 유지됩니다. AWS Data Lifecycle Manager(DLM)도 동일한 역할을 하지만, 커스텀 태그 로직이나 알림 연동이 필요하면 직접 작성하는 편이 유연합니다.
저장 시 암호화 비교: SSE-S3 vs SSE-KMS vs SSE-C
S3에 저장되는 모든 객체는 암호화하는 것이 기본입니다. 세 가지 서버 측 암호화 방식 중 운영 복잡도와 규제 요건에 맞는 것을 고릅니다.
| 항목 | SSE-S3 | SSE-KMS | SSE-C |
|---|---|---|---|
| 키 관리 주체 | AWS 완전 관리 | AWS KMS (고객 제어) | 고객이 직접 제공 |
| 키 교체 | 자동 (연 1회) | 자동 또는 수동 | 고객 책임 |
| 감사 로그 | S3 서버 로그만 | CloudTrail에 키 사용 기록 | 없음 (고객 측 기록 필요) |
| 추가 비용 | 없음 | KMS 요청당 과금 | 없음 |
| 규제 적합성 | 기본 수준 | 높음 (HIPAA, PCI-DSS 등) | 최고 (키 완전 분리) |
| 운영 복잡도 | 낮음 | 중간 | 높음 |
| 교차 계정 접근 | 버킷 정책만으로 가능 | KMS 키 정책 추가 필요 | 요청마다 키 전달 필요 |
대부분의 워크로드에서는 SSE-S3로 충분합니다. 감사 추적이 필요하거나 키 접근을 세밀하게 통제해야 하면 SSE-KMS를 씁니다. SSE-C는 키를 AWS에 전혀 맡기지 않아야 하는 극단적인 규제 환경에서만 사용하며, 키를 분실하면 데이터를 복구할 수 없으므로 키 관리 체계가 선행되어야 합니다.
# SSE-KMS로 기본 암호화 설정
aws s3api put-bucket-encryption \
--bucket my-app-prod \
--server-side-encryption-configuration '{
"Rules": [{
"ApplyServerSideEncryptionByDefault": {
"SSEAlgorithm": "aws:kms",
"KMSMasterKeyID": "arn:aws:kms:us-east-1:123456789012:key/abcd-1234"
},
"BucketKeyEnabled": true
}]
}'BucketKeyEnabled: true는 S3 버킷 키를 활성화하여 KMS 호출 횟수를 줄이고 비용을 낮춥니다. 대량 객체를 다루는 버킷에서는 반드시 켜 두는 것이 좋습니다.
스토리지 운영 설정 예시
아래는 실제 운영에서 자주 쓰는 검증 명령과 IaC 예시입니다. 핵심은 저장소를 생성한 뒤 접근 제어, 암호화, 수명 주기, 복구 가능성을 함께 점검하는 흐름을 고정하는 것입니다.
# AWS S3 기본 보안/보관 설정 확인
aws s3api get-public-access-block --bucket my-app-prod
aws s3api get-bucket-encryption --bucket my-app-prod
aws s3api get-bucket-versioning --bucket my-app-prod
# Azure Blob 컨테이너 접근 수준 확인
az storage container show --account-name mystorageacct --name uploads --query properties.publicAccess
# Google Cloud Storage 수명 주기 확인
gcloud storage buckets describe gs://my-app-prod --format="value(lifecycle)"resource "aws_s3_bucket" "app" {
bucket = "my-app-prod"
}
resource "aws_s3_bucket_versioning" "app" {
bucket = aws_s3_bucket.app.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_s3_bucket_lifecycle_configuration" "app" {
bucket = aws_s3_bucket.app.id
rule {
id = "logs-tiering"
status = "Enabled"
filter { prefix = "logs/" }
transition {
days = 30
storage_class = "STANDARD_IA"
}
transition {
days = 90
storage_class = "GLACIER"
}
}
}| 비교 항목 | S3 Standard | S3 Standard-IA | S3 Glacier Instant Retrieval |
|---|---|---|---|
| 접근 빈도 | 높음 | 중간~낮음 | 낮음 |
| 조회 지연 | 낮음 | 낮음 | 중간 |
| 저장 단가 경향 | 높음 | 중간 | 낮음 |
| 주요 용도 | 운영 데이터 | 장기 로그 | 감사/보관 데이터 |
텍스트 아키텍처 다이어그램:App -> S3(Standard) -> Lifecycle(30일) -> S3 IA -> Lifecycle(90일) -> Glacier -> Restore Job
처음 질문으로 돌아가기
- 객체, 블록, 파일, 아카이브 스토리지는 각각 무엇이 다를까요? 접근 방식(키-값 vs 블록 I/O vs POSIX 파일시스템 vs 장기 보관)과 지연 시간, 확장 모델이 근본적으로 다릅니다. 워크로드의 I/O 패턴에 맞는 유형을 고르는 것이 핵심입니다.
- 내구성과 가용성은 왜 같은 말이 아닐까요? 내구성은 데이터가 손실 없이 보존될 확률이고, 가용성은 지금 당장 접근 가능한지를 뜻합니다. Glacier는 내구성 99.999999999%이지만 즉시 읽기는 불가능합니다.
- S3 라이프사이클 정책은 어떤 문제를 해결할까요? 시간이 지나면서 접근 빈도가 줄어드는 데이터를 자동으로 저렴한 계층으로 이동시켜, 수동 정리 없이 비용을 지속적으로 절감합니다.
시리즈 목차
- Cloud Computing 101 (1/10): Cloud Computing이란 무엇인가?
- Cloud Computing 101 (2/10): IaaS, PaaS, SaaS
- Cloud Computing 101 (3/10): Region과 Availability Zone
- Cloud Computing 101 (4/10): Compute
- Storage (현재 글)
- Network (예정)
- Identity와 Security (예정)
- Monitoring (예정)
- Cost Management (예정)
- Cloud Architecture 기초 (예정)
참고 자료
'Software Engineering' 카테고리의 다른 글
| Cloud Computing 101 (7/10): Identity와 Security (0) | 2026.06.16 |
|---|---|
| Cloud Computing 101 (6/10): Network (0) | 2026.06.16 |
| Cloud Computing 101 (4/10): Compute (0) | 2026.06.08 |
| Cloud Computing 101 (3/10): Region과 Availability Zone (0) | 2026.06.08 |
| Cloud Computing 101 (2/10): IaaS, PaaS, SaaS (0) | 2026.06.08 |
- Total
- Today
- Yesterday
- openAI
- AI Evaluation
- backend
- DevOps
- Production
- frontend
- Computer Science
- vector search
- docker
- Architecture
- langchain
- Agent
- embeddings
- Cloud
- rag
- testing
- QUALITY
- containers
- webdevelopment
- reliability
- http
- softwaredesign
- Python
- Tool Use
- ai agent
- AZURE
- Kubernetes
- DesignPatterns
- LLM
- APIDesign
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |