

티스토리 뷰
agent가 한두 번의 tool call로 끝나면 기억 문제는 크게 드러나지 않습니다. 하지만 대화가 길어지고, 여러 단계의 workflow가 누적되고, 사용자가 후속 질문을 던지기 시작하면 금세 다른 문제가 생깁니다. 이전 맥락을 얼마나 유지해야 하는지, 어떤 정보는 버려도 되는지, 무엇을 구조화된 상태로 저장해야 하는지가 중요해집니다.
많은 입문자가 memory와 state를 같은 것으로 다루지만, 운영에서는 둘을 분리하는 편이 훨씬 안전합니다. memory는 과거의 정보를 보존하는 방식에 가깝고, state는 현재 실행 위치를 나타내는 구조화된 레코드에 가깝습니다.
또한 모든 것을 프롬프트에 계속 붙여 넣는 방식은 오래 버티지 못합니다. context window는 유한하고, token 비용은 선형 이상으로 체감되며, 오래된 history가 오히려 최신 결정을 흐릴 수 있기 때문입니다.
이 글은 AI Agent 101 시리즈의 다섯 번째 글입니다.
이 글에서는 short-term memory, long-term memory, state를 분리해서 보고 어떤 정보를 어디에 둘지 결정하는 기준을 정리하겠습니다.
이 글에서 다룰 문제
- short-term memory와 long-term memory는 무엇이 다르고 언제 각각 필요할까요?
- history를 어디까지 유지하고 어디서 압축해야 할까요?
- state와 memory를 구분하지 않으면 어떤 오류가 생길까요?
- 외부 저장소는 vector DB, key-value store, relational DB 중 무엇을 언제 고르면 좋을까요?
- context window가 부족할 때 가장 먼저 줄여야 할 것은 무엇일까요?
왜 이 글이 중요한가
memory 설계는 agent의 체감 품질을 결정합니다. 사용자가 같은 말을 반복하지 않게 해 주고, 긴 작업을 중간에 잊지 않게 해 주며, 후속 질문을 자연스럽게 이어 주기 때문입니다. 동시에 잘못 설계하면 비용과 오류를 폭발시키는 가장 빠른 길이 되기도 합니다.
운영에서는 특히 state 구분이 중요합니다. history만 길게 들고 가면 현재 workflow 위치를 복원하기 어렵고, 반대로 state만 남기면 사용자 선호나 이전 결정 근거를 잃기 쉽습니다. 두 층을 분리해야 재시작, checkpoint, retry가 모두 쉬워집니다.
또한 memory는 evaluation과도 연결됩니다. 어떤 정보를 저장했는지, 언제 불러왔는지, retrieval이 실제로 도움이 되었는지를 측정하지 않으면 "기억을 붙였더니 좋아졌다"는 막연한 인상만 남고 최적화는 멈춥니다.
Memory와 State를 이해하는 가장 좋은 방법: 과거 보존과 현재 위치를 분리하는 것입니다
memory를 전부 하나의 "기억"으로 묶어 생각하면 설계가 금방 엉킵니다. 저는 보통 두 질문으로 분리합니다. 첫째, 무엇을 오래 보관할 것인가. 둘째, 지금 어디까지 왔는가. 첫 번째가 memory이고 두 번째가 state입니다.
이 구분이 있으면 데이터 저장소 선택도 쉬워집니다. 사용자 선호, 과거 요약, 지식 스니펫은 long-term memory 후보이고, 현재 단계, 완료 목록, 남은 작업은 state 후보입니다. 둘을 같은 구조에 섞어 두면 읽기도 어렵고 변경 충돌도 많아집니다.
실무에서는 "모든 대화를 다 넣자"보다 "현재 턴 판단에 필요한 최소 기억과 현재 위치만 넣자"가 훨씬 오래 버팁니다.
좋은 memory 설계는 많이 기억하는 것이 아니라, 오래 보관할 정보와 지금 실행에 필요한 상태를 분리해서 필요한 순간에만 꺼내 쓰는 것입니다.
메모리와 상태 분리
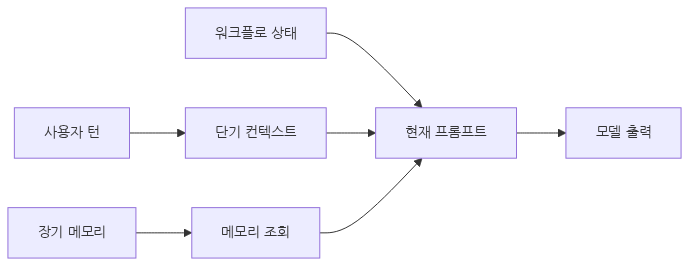
핵심 개념
memory와 state를 한 장의 흐름으로 보면 설계 경계가 선명해집니다

short-term memory는 현재 대화의 working set이고, state는 현재 실행 위치이며, long-term memory는 다음 세션에도 남겨 둘 정보라는 구분을 먼저 고정해 두면 설계가 덜 흔들립니다.
short-term memory는 현재 세션 안의 작업 맥락입니다
from typing import List, Dict
class ShortTermMemory:
"""Short-term memory: retained only during current session"""
def __init__(self, system_prompt: str):
self.messages: List[Dict[str, str]] = [
{"role": "system", "content": system_prompt}
]
def add_user_message(self, content: str):
"""Add user message"""
self.messages.append({"role": "user", "content": content})
def add_assistant_message(self, content: str):
"""Add agent response"""
self.messages.append({"role": "assistant", "content": content})
def get_context(self) -> List[Dict[str, str]]:
"""Return current context"""
return self.messages
def clear(self):
"""Clear memory on session end"""
system_msg = self.messages[0]
self.messages = [system_msg]
# Usage example
memory = ShortTermMemory(system_prompt="You are a helpful assistant.")
memory.add_user_message("What's the weather today?")
memory.add_assistant_message("Today's weather in Seoul is sunny.")
memory.add_user_message("How about tomorrow?")
# Agent remembers previous conversation ("weather today") and understands "tomorrow" refers to weather
print(f"Message count: {len(memory.get_context())}") # 4 (system + user + assistant + user)short-term memory는 가장 구현이 쉽지만 가장 빨리 비대해지는 층이기도 합니다. 대화가 길어질수록 그대로 LLM에 보내는 방식은 비싸지고, 오래된 메시지가 현재 판단을 왜곡할 가능성도 커집니다. 그래서 sliding window나 summary compaction이 뒤따라야 합니다.
long-term memory는 세션 밖으로 꺼낸 정보입니다
import json
from datetime import datetime
from typing import List, Dict, Optional
class LongTermMemory:
"""Long-term memory: permanently stored in external storage"""
def __init__(self, storage_path: str = "memory.json"):
self.storage_path = storage_path
self.memories: Dict[str, List[Dict]] = self._load()
def _load(self) -> Dict[str, List[Dict]]:
"""Load memory from storage"""
try:
with open(self.storage_path, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
return {}
def _save(self):
"""Save memory to storage"""
with open(self.storage_path, 'w', encoding='utf-8') as f:
json.dump(self.memories, f, ensure_ascii=False, indent=2)
def add_memory(self, user_id: str, key: str, value: str):
"""Add information to user's memory"""
if user_id not in self.memories:
self.memories[user_id] = []
self.memories[user_id].append({
"key": key,
"value": value,
"timestamp": datetime.now().isoformat()
})
self._save()
def retrieve_memory(self, user_id: str, key: Optional[str] = None) -> List[Dict]:
"""Retrieve user's memory"""
if user_id not in self.memories:
return []
memories = self.memories[user_id]
if key:
# Return only memories matching the key
return [m for m in memories if m["key"] == key]
return memorieslong-term memory의 핵심은 모두를 매 턴 넣지 않는다는 점입니다. 저장은 넉넉하게 하되, retrieval은 좁게 해야 합니다. 사용자 선호, 과거 작업 요약, 반복적으로 쓰는 사실처럼 세션 밖에서도 가치가 남는 것만 저장하는 편이 좋습니다.
실제 시스템은 둘을 조합하되 state를 별도로 둡니다
class HybridMemory:
"""Short-term memory + long-term memory combined"""
def __init__(self, user_id: str, system_prompt: str):
self.user_id = user_id
self.short_term = ShortTermMemory(system_prompt)
self.long_term = LongTermMemory()
def start_session(self):
"""Load relevant information from long-term memory on session start"""
memories = self.long_term.retrieve_memory(self.user_id)
if memories:
# Add long-term memory content to system prompt
context = "Previous user preferences:
"
for mem in memories:
context += f"- {mem['key']}: {mem['value']}
"
self.short_term.messages[0]["content"] += f"
{context}"
def add_user_message(self, content: str):
"""Add user message"""
self.short_term.add_user_message(content)
def add_assistant_message(self, content: str):
"""Add agent response"""
self.short_term.add_assistant_message(content)
def save_important_info(self, key: str, value: str):
"""Save important information to long-term memory"""
self.long_term.add_memory(self.user_id, key, value)
def get_context(self) -> List[Dict[str, str]]:
"""Return current context"""
return self.short_term.get_context()
def end_session(self):
"""Session end: clear short-term memory"""
self.short_term.clear()이 예제는 memory 결합만 보여 주지만, production에서는 여기에 별도 state 객체를 함께 둡니다. 예를 들어 current_step, completed_steps, pending_actions, retry_count 같은 필드는 history 대신 state에 두는 편이 낫습니다. 그래야 재개와 복구가 쉬워집니다.
재시작 복구를 먼저 검증해 두면 state의 역할이 분명해집니다
아래 예시는 long-running workflow가 중간에 끊겨도 state.json만 있으면 어디서 다시 시작할지 복원하는 가장 작은 형태입니다.
import json
from pathlib import Path
STATE_PATH = Path("state.json")
def save_state(step: str, completed: list[str]) -> None:
STATE_PATH.write_text(
json.dumps({"current_step": step, "completed": completed}, ensure_ascii=False, indent=2),
encoding="utf-8",
)
def load_state() -> dict:
if not STATE_PATH.exists():
return {"current_step": "collect", "completed": []}
return json.loads(STATE_PATH.read_text(encoding="utf-8"))
state = load_state()
print("before:", state)
if state["current_step"] == "collect":
state["completed"].append("collect")
state["current_step"] = "summarize"
save_state(state["current_step"], state["completed"])
reloaded = load_state()
print("after:", reloaded)예상 출력:
before: {'current_step': 'collect', 'completed': []}
after: {'current_step': 'summarize', 'completed': ['collect']}이 예시는 단순하지만 중요한 사실을 보여 줍니다. workflow 복구에 필요한 정보는 대화 원문 전체가 아니라 현재 위치와 완료 목록인 경우가 많습니다. 그래서 state를 history와 분리해 두면 복구 경로가 훨씬 짧아집니다.
context window는 저장소가 아니라 working set입니다
- 현재 턴 의사결정에 직접 필요한 내용만 넣습니다.
- 오래된 대화는 summary로 압축합니다.
- 자주 재사용하는 사실은 long-term memory로 이동합니다.
- 현재 실행 위치는 별도 state 구조로 유지합니다.
- memory retrieval은 무조건 많이 넣기보다 precision을 우선합니다.
failure mode를 state 관점에서 먼저 보면 memory 설계가 단단해집니다
- history만 길게 쌓고 current step을 따로 저장하지 않으면 재시작 후 어느 단계였는지 복원하기 어렵습니다.
- long-term memory에 사소한 대화까지 모두 저장하면 retrieval precision이 떨어져 오히려 현재 판단을 흐립니다.
- summary를 너무 공격적으로 줄이면 사용자의 제약 조건과 이전 결정 근거가 사라집니다.
- 반대로 아무 압축도 하지 않으면 context window와 비용이 먼저 한계에 닿습니다.
실무에서는 "다음 step 결정에 꼭 필요한가", "다음 세션에도 다시 써야 하는가" 두 질문으로 memory 저장 여부를 나누는 편이 좋습니다. 첫 질문에만 해당하면 short-term이나 state로, 두 번째 질문까지 해당하면 long-term memory로 보내는 식입니다.
흔히 헷갈리는 지점
- history를 길게 유지하면 더 똑똑해질 것 같지만, 실제로는 비용과 혼선을 함께 키울 수 있습니다.
- memory와 state를 같은 dict에 넣으면 단기적으로 편해 보여도 재시도와 복구가 어려워집니다.
- long-term memory를 벡터 DB 하나로 끝내려 하기 쉽지만, 단순 key-value가 더 맞는 정보도 많습니다.
- 저장만 잘하면 된다고 생각하기 쉽지만, retrieval precision이 낮으면 오히려 해로운 컨텍스트가 들어옵니다.
- context window를 꽉 채우는 것이 활용이라고 생각하기 쉽지만, 실제로는 working set을 줄이는 편이 더 안정적입니다.
운영 체크리스트
- short-term memory와 long-term memory의 저장 기준이 분리되어 있는가
- 현재 workflow 위치를 나타내는 state 구조가 별도로 존재하는가
- 오래된 history를 요약하거나 압축하는 정책이 있는가
- long-term memory retrieval 결과를 그대로 넣지 않고 필터링하는가
- memory 사용량, retrieval hit, context length를 측정하고 있는가
정리
memory와 state는 agent를 오래 버티게 만드는 기반입니다. 하지만 둘을 구분하지 않으면 금세 비용이 커지고, 현재 위치를 잃고, 재시도와 복구가 어려워집니다. 그래서 좋은 설계의 출발점은 기억을 많이 남기는 것이 아니라 기억의 종류를 나누는 것입니다.
short-term memory는 현재 세션의 working set이고, long-term memory는 나중에 다시 꺼내 쓸 자산이며, state는 지금 어디까지 왔는지를 나타내는 제어 정보입니다. 이 세 층이 분리되면 workflow와 reliability와 evaluation이 모두 단단해집니다.
다음 글에서는 이 기반 위에서 여러 agent가 협업하는 multi-agent 시스템을 살펴봅니다. 역할이 늘어날수록 누가 어떤 state를 읽고 어떤 memory를 공유할지 더 명확히 설계해야 하기 때문입니다.
시리즈 목차
- AI Agent란 무엇인가?
- 컨텍스트 엔지니어링
- Tool Use 기초
- Agent Workflow 설계
- Memory와 State (현재 글)
- Multi-Agent 시스템 (예정)
- Agent 평가 (예정)
- 에러 처리와 안정성 (예정)
- 운영 (예정)
- 첫 Agent 만들기 (예정)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| AI Agent 101 : Agent 평가 (0) | 2026.05.16 |
|---|---|
| AI Agent 101 : Multi-Agent 시스템 (0) | 2026.05.16 |
| AI Agent 101 : Agent Workflow 설계 (0) | 2026.05.16 |
| AI Agent 101 : Tool Use 기초 (0) | 2026.05.16 |
| AI Agent 101 : 컨텍스트 엔지니어링 (0) | 2026.05.16 |
- Total
- Today
- Yesterday
- backend
- ai agent
- Prompt engineering
- AZURE
- APIDesign
- LLM
- Architecture
- Cleancode
- webdevelopment
- Computer Science
- rag
- http
- Refactoring
- AI Evaluation
- reliability
- softwaredesign
- Python
- openAI
- ai safety
- Cloud
- harness
- Azure Functions
- langchain
- Production
- DesignPatterns
- Agent
- DevOps
- vector search
- embeddings
- Tool Use
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |