

티스토리 뷰
평가를 시작하겠다고 마음먹은 팀이 가장 먼저 부딪히는 벽은 지표보다 데이터입니다. 무엇을 점수화할지는 이야기할 수 있어도, 무엇을 입력으로 삼아야 할지는 금방 막히기 때문입니다.
현업에서는 이 지점에서 자주 두 가지 실수가 나옵니다. 하나는 데모에 잘 맞는 예제만 모아 놓고 평가셋이라고 부르는 경우입니다. 다른 하나는 실제 트래픽을 넣고 싶지만 개인정보와 라벨링 부담 때문에 아예 시작을 미루는 경우입니다.
제가 본 강한 팀들은 평가 데이터셋을 정답 모음집으로 만들지 않았습니다. 대신 사용자 분포를 닮은 본류 사례와, 자주 오지는 않지만 깨지면 큰일 나는 실패 사례를 함께 관리했습니다. 이 균형이 없으면 평균 점수는 좋아도 서비스는 계속 흔들립니다.
이 글은 AI Evaluation 101 시리즈의 2번째 글입니다.
여기서는 50~200건 규모의 출발용 평가 데이터셋을 어떻게 설계하고, 어디서 수집하고, 어떤 방식으로 라벨을 붙여야 하는지 정리하겠습니다.
이 글에서 다룰 문제
- 좋은 평가 데이터셋은 실제 트래픽 분포와 엣지 케이스를 어떻게 함께 담아야 할까요?
- 운영 로그, 실패 사례, 의도적 적대 사례는 각각 어떤 역할을 맡을까요?
- Smoke test, 회귀 테스트, 모델 비교 실험에 필요한 데이터셋 크기는 왜 다를까요?
expected필드는 언제 exact, keywords, rubric 중 무엇으로 채워야 할까요?- 평가 데이터셋을 JSONL과 git으로 버전 관리해야 하는 이유는 무엇일까요?
왜 이 글이 중요한가
데이터셋이 빈약하면 지표가 정교해도 결과를 믿기 어렵습니다. 프롬프트 작성자가 고른 보기 좋은 사례만 모아 두면 모델은 늘 좋아 보일 수밖에 없습니다. 운영 품질을 알고 싶다면 운영에 가까운 표본이 먼저 필요합니다.
또 하나 중요한 점은 실패 사례의 축적입니다. 한 번 크게 깨진 입력을 평가셋에 넣지 않으면 팀은 같은 사고를 반복해서 다시 배웁니다. 실제로 좋은 평가셋은 성능 측정 도구이면서 동시에 사고 기록 저장소 역할도 합니다.
그래서 데이터셋 설계는 단순한 준비 작업이 아닙니다. 무엇을 지키고 싶은지, 어떤 실패를 다시는 반복하지 않겠는지 팀이 합의하는 첫 운영 문서에 가깝습니다.
평가 데이터셋을 이해하는 가장 좋은 방법: 모델 시험지가 아니라 운영 표본으로 봐야 합니다
이 주제는 개별 기법을 외우기보다 먼저 어떤 운영 문제를 풀기 위한 장치인지 붙잡아 두는 편이 이해가 빠릅니다. 데이터셋이 빈약하면 지표가 정교해도 결과를 믿기 어렵습니다. 프롬프트 작성자가 고른 보기 좋은 사례만 모아 두면 모델은 늘 좋아 보일 수밖에 없습니다. 운영 품질을 알고 싶다면 운영에 가까운 표본이 먼저 필요합니다.
좋은 평가 데이터셋은 멋진 예시 모음이 아닙니다. 실제 사용 분포를 닮되, 한 번 깨지면 큰 사고로 이어지는 모서리 사례를 일부러 섞어 둔 운영용 표본입니다.
이 관점을 먼저 잡아 두면 뒤에 나오는 코드와 지표를 기능 설명이 아니라 운영 설계 관점에서 읽을 수 있습니다. 결국 중요한 것은 수치 이름보다, 그 수치가 어떤 의사결정을 가능하게 하느냐입니다.
핵심 개념

좋은 평가 데이터셋이란 무엇인가요?

좋은 eval set은 두 가지를 동시에 만족합니다.
- Production 트래픽의 분포를 닮습니다: 사용자가 실제로 보내는 질문의 비율과 비슷해야 합니다.
- Edge case를 충분히 포함합니다: 평소엔 드물지만 깨지면 큰 사고가 나는 케이스를 의도적으로 모아둡니다.
이 둘이 같이 있어야 "평균 점수는 좋은데 한 케이스에서 처참하게 깨지는" 상황을 잡을 수 있습니다.
from dataclasses import dataclass
@dataclass
class EvalExample:
id: str
input: dict
expected: dict | None # only filled when a deterministic answer exists
category: str # one of "happy_path", "edge_case", "adversarial"
notes: str = ""category를 명시적으로 붙이면 "edge case 점수만 따로 보기"가 가능해집니다. 평균만 보면 다수 케이스가 묻어 가립니다.
어디서 데이터를 가져오나요?

3가지 출처를 조합합니다.
1. Production trace에서 샘플링
가장 좋은 출처는 실제 사용자 입력입니다. 매주 production log에서 무작위 50건을 추출해 eval set 후보로 모읍니다.
import random
def sample_from_production(traces: list[dict], n: int = 50) -> list[dict]:
return random.sample(traces, min(n, len(traces)))PII가 들어 있다면 마스킹하거나 합성 데이터로 변환합니다 (Ep9 Observability 참조).
2. 실패 케이스 모으기
사용자 불만, on-call에서 잡힌 사고, 내부 dogfooding에서 깨진 케이스를 모두 eval set에 넣습니다. "한 번 깨진 건 다시 깨지지 않게 하는" 회귀 테스트의 시작입니다.
def add_failure_case(eval_set: list[dict], failed_input: dict, expected: dict, source: str):
eval_set.append({
"id": f"regression-{len(eval_set)+1:04d}",
"input": failed_input,
"expected": expected,
"category": "regression",
"notes": f"From: {source}",
})3. 의도적으로 만든 adversarial 케이스
도메인 지식을 가진 사람이 "이건 깨질 것 같다"고 손으로 만든 케이스입니다. Prompt injection, 모호한 질문, 답이 없는 질문 등이 여기 들어갑니다.
몇 건이 필요한가요?

크기는 목적에 따라 다릅니다.
| 목적 | 권장 크기 | 비고 |
|---|---|---|
| Smoke test (CI에서 매 PR마다) | 10-30 | 빠르게 돌고, 명백한 회귀만 잡습니다 |
| 회귀 테스트 (배포 전) | 100-300 | 차원별로 의미 있는 점수를 냅니다 |
| 모델 비교 (gpt-4o vs claude) | 300-1000 | 통계적으로 유의미한 결론이 가능합니다 |
| 학술 벤치마크 | 1000+ | 일반화 가능성 주장에 필요합니다 |
처음에는 10-30건으로 시작하고, 매주 production trace에서 5-10건씩 추가하면 3개월 안에 200건에 도달합니다.
라벨링 — expected를 어떻게 채우나요?
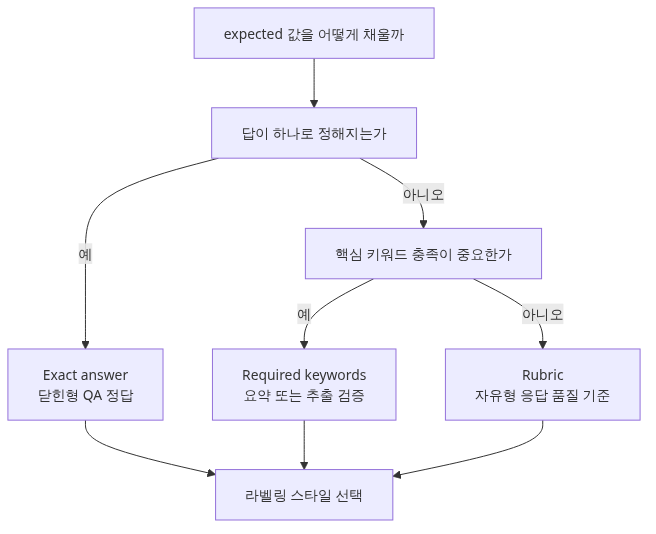
라벨링 방식은 3가지가 있고, 케이스마다 다른 방식을 쓸 수 있습니다.
@dataclass
class Label:
style: str # "exact", "keywords", "rubric"
payload: dict- Exact answer: "한국의 수도는?" → "서울". 정답이 하나뿐일 때 사용합니다.
- Required keywords: 요약 결과에 반드시 들어가야 할 단어 리스트.
- Rubric: 정답이 여럿일 때 "정확성 5점 만점 중 X점" 같은 차원별 점수 (Ep5에서 자세히 다룹니다).
examples = [
EvalExample(
id="qa-001",
input={"question": "What is the capital of Korea?"},
expected={"style": "exact", "answer": "Seoul"},
category="happy_path",
),
EvalExample(
id="summary-001",
input={"text": "..."},
expected={"style": "keywords", "must_include": ["microservice", "latency"]},
category="happy_path",
),
EvalExample(
id="advice-001",
input={"question": "How should I structure my React app?"},
expected={"style": "rubric"},
category="edge_case",
),
]Eval set을 어떻게 버전 관리하나요?
Eval set은 코드와 함께 버전 관리되어야 합니다. JSONL 파일로 저장하고 git에 커밋하세요.
import json
from pathlib import Path
def save_eval_set(eval_set: list[EvalExample], path: Path):
with path.open("w") as f:
for ex in eval_set:
f.write(json.dumps({
"id": ex.id,
"input": ex.input,
"expected": ex.expected,
"category": ex.category,
"notes": ex.notes,
}, ensure_ascii=False) + "\n")
def load_eval_set(path: Path) -> list[EvalExample]:
with path.open() as f:
return [EvalExample(**json.loads(line)) for line in f]파일명에 버전을 박는 것도 좋은 습관입니다: evals/customer-support/v3.jsonl. 새 버전을 만들 때 옛 버전을 지우지 말고 이름을 늘리세요.
이 코드에서 먼저 봐야 할 점
EvalExample에category를 명시한 부분이 핵심입니다. 평균 점수만 보면 엣지 케이스가 묻히기 때문에, 카테고리별 분리가 먼저 필요합니다.- 세 가지 데이터 소스 가운데 운영 샘플과 실패 사례를 어떻게 섞는지 보시면 평가셋이 연구용 데이터가 아니라 운영 자산이라는 감각이 잡힙니다.
save_eval_set예제는 평가셋이 코드 옆에서 버전 관리되어야 한다는 점을 보여 줍니다. 바뀐 모델은 기록하지 않으면서 바뀐 평가셋만 모호하게 두면 비교가 무의미해집니다.
이 세 지점을 먼저 읽고 나면 세부 구현과 지표 해석이 훨씬 빨라집니다. 코드가 길어 보여도 운영 질문은 대개 여기로 다시 돌아옵니다.
어디서 자주 헷갈릴까요?
- Eval set을 prompt 작성자가 만듦: 자기 prompt에 유리한 케이스만 모이고, "잘된다"는 잘못된 결론이 나옵니다. 다른 팀원이나 production에서 가져오세요.
- Happy path만 모음: edge case가 없으면 "평균 90%인데 1% 사용자가 망가지는" 상황을 못 잡습니다. category 비율을 의도적으로 관리하세요.
- PII를 그대로 저장: 실제 사용자 데이터를 git에 커밋하면 큰 사고입니다. 라벨링 전에 마스킹하세요.
expected를 한 가지 방식으로만 채움: 모든 케이스에 exact match를 강제하면 자유 형식 답이 모두 0점이 됩니다. 케이스별로 적절한 라벨 스타일을 고르세요.- Eval set을 한 번 만들고 안 갱신: production 트래픽 분포가 바뀌면 옛 eval set은 의미가 없어집니다. 매주 5-10건씩 갱신하세요.
현업에서 제가 가장 자주 보는 문제는 결과 숫자만 보고 원인 분해를 건너뛰는 습관입니다. 평가가 개선을 돕지 못하고 보고서용 숫자로만 남는 순간, 팀은 다시 감각에 의존하게 됩니다.
첫 번째 운영 체크리스트
- 운영 로그에서 매주 새 사례를 일정량 수집하는 흐름이 있는가
- 실패 케이스를 별도 카테고리로 보존하고 있는가
- 개인정보가 포함된 입력을 마스킹하거나 합성 데이터로 바꾸는 기준이 있는가
- 정답 형식이 하나가 아닌 사례를 rubric으로 분리할 준비가 되어 있는가
- 평가셋 파일 버전과 모델 버전을 함께 기록하고 있는가
실무에서는 이렇게 생각한다
실무에서는 '몇 건이면 충분한가'보다 '무엇이 빠져 있으면 위험한가'를 먼저 봅니다. 고객센터 봇이라면 상위 문의 유형과 과거 장애 사례가 빠진 데이터셋은 크기가 커도 약합니다.
또한 평가셋 작성자를 분리하는 원칙이 중요합니다. 프롬프트를 만든 사람이 자기 평가셋까지 고르면 결과는 쉽게 낙관적으로 기울어집니다. 최소한 운영 로그나 다른 팀원의 리뷰를 끼워 넣는 편이 안전합니다.
다음 글의 지표 논의도 결국 이 데이터셋 위에서만 의미가 있습니다. 잘못 뽑은 입력에 정교한 지표를 얹어 봐야 팀은 잘못된 확신만 더 크게 얻게 됩니다.
정리: 좋은 평가셋은 평균을 재는 도구이면서 사고를 기억하는 저장소입니다
- 좋은 eval set은 production 분포 + edge case를 함께 담습니다.
- 출처는 production trace 샘플링, 실패 케이스, 의도적 adversarial 3가지를 조합하세요.
- Smoke 10-30건, 회귀 100-300건, 모델 비교 300-1000건이 목표 크기입니다.
- 라벨은 exact, keywords, rubric 3가지 스타일을 케이스별로 골라 쓰세요.
- JSONL로 git에 커밋하고 파일명에 버전을 박으세요.
이제 데이터셋의 바탕이 잡혔다면, 다음 글에서는 여기에 어떤 결정적 지표를 얹을 수 있는지 봅니다. Exact Match, F1, BLEU, ROUGE가 어디까지 유효하고 어디서부터 위험해지는지가 다음 단계입니다.
운영 체크리스트
- 상위 사용 패턴과 과거 장애 사례를 모두 평가셋에 포함하기
- 카테고리별 점수를 따로 볼 수 있도록 메타데이터 넣기
- 정답 형식이 다른 사례를 한 가지 라벨 스타일로 강제하지 않기
- 평가셋을 코드와 함께 버전 관리하기
- 주간 단위로 새 운영 사례를 보충하는 습관 만들기
AI Evaluation 101 시리즈
- 왜 LLM 애플리케이션을 평가해야 하는가
- 평가 데이터셋 설계하기 (현재 글)
- 결정적 지표 — Exact Match, BLEU, ROUGE (예정)
- LLM-as-Judge — 모델로 모델을 평가하기 (예정)
- Rubric 기반 채점 설계 (예정)
- RAG 시스템 평가하기 (예정)
- 에이전트 평가하기 — 단일 응답이 아닌 trajectory (예정)
- 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (예정)
- LLM A/B 테스팅 — 어느 prompt가 더 나은가 (예정)
- 운영 환경에서의 지속적 평가 (예정)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| AI Evaluation 101 : LLM-as-Judge — 모델로 모델을 평가하기 (0) | 2026.05.18 |
|---|---|
| AI Evaluation 101 : 결정적 지표 — Exact Match, BLEU, ROUGE (0) | 2026.05.18 |
| AI Evaluation 101 : 왜 LLM 애플리케이션을 평가해야 하는가 (0) | 2026.05.18 |
| Harness Engineering 101 : Production Harness — 운영 가능한 Agent 작업 환경 만들기 (0) | 2026.05.17 |
| Harness Engineering 101 : Observability — Agent 작업을 추적하고 재현하기 (0) | 2026.05.17 |
- Total
- Today
- Yesterday
- reliability
- Agent
- Cloud
- Python
- http
- Prompt engineering
- DevOps
- vector search
- serverless
- AZURE
- Architecture
- openAI
- DesignPatterns
- langchain
- ai agent
- ai safety
- embeddings
- softwaredesign
- Tool Use
- Computer Science
- AI Evaluation
- rag
- LLM
- backend
- APIDesign
- Refactoring
- Cleancode
- Azure Functions
- harness
- Production
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |