

티스토리 뷰
이 시리즈에서 살펴본 컴퓨트, 스토리지, 네트워크, 보안, 모니터링, 비용은 각각 따로 존재하는 지식이 아닙니다. 실제 시스템에서는 이 조각들이 한 구조 안에서 함께 움직입니다.
이 글은 Cloud Computing 101 시리즈의 마지막 글입니다.
좋은 아키텍처는 화려한 서비스 조합이 아니라 변경이 안전하고, 장애가 국소화되며, 운영이 반복 가능하다는 점에서 드러납니다. 그래서 마지막 글에서는 기능 목록보다 구조적 원칙에 집중하는 편이 더 중요합니다.
여기서는 Well-Architected의 여섯 가지 관점을 기준으로, 앞선 내용이 하나의 클라우드 아키텍처로 어떻게 이어지는지 정리하겠습니다.
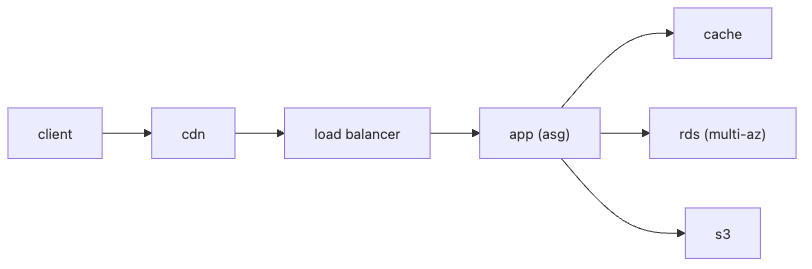
Cloud Computing 101 10장 흐름 개요
좋은 아키텍처는 완벽한 설계가 아니라, 운영 과정에서 계속 배우고 개선하는 문화입니다.
먼저 던지는 질문
- Well-Architected의 여섯 기둥은 각각 무엇을 보라고 말할까요?
- 기본적인 다층 웹 아키텍처는 어떤 모습일까요?
- Stateless와 Stateful을 왜 분리해야 할까요?
왜 중요한가
같은 기능이라도 아키텍처에 따라 비용이 몇 배 차이 날 수 있고, 장애의 범위도 달라질 수 있습니다. 단일 서버에 묶인 시스템은 작은 변경도 두렵고, 반대로 계층이 분리된 구조는 변경과 복구가 훨씬 안전합니다.
아키텍처는 추상적인 다이어그램이 아니라 실제 운영 비용과 팀 생산성을 결정하는 선택의 집합입니다. 그래서 마지막 단계에서는 각 서비스 지식을 한 그림으로 묶어 보는 훈련이 필요합니다.
한눈에 보는 개념
이 그림은 전형적인 다층 웹 구조를 보여 줍니다. CDN이 정적 콘텐츠와 글로벌 읽기 트래픽을 흡수하고, ALB가 요청을 분산하며, 앱 계층은 Stateless하게 확장되고, 데이터 계층은 캐시, DB, 오브젝트 스토리지로 역할이 나뉩니다.
[사용자] ──→ [CDN / CloudFront]
│
▼
[ALB - HTTPS 종료]
┌──────┴──────┐
▼ ▼
[App AZ-a] [App AZ-b] ← Stateless Auto Scaling Group
│ │
└──────┬──────┘
│
┌─────────┼─────────┐
▼ ▼ ▼
[Redis] [RDS Primary] [S3]
│
▼
[RDS Standby] ← Multi-AZ 자동 장애 조치Web 계층, App 계층, Data 계층이 분리되어 있으면 각 계층을 독립적으로 확장하거나 교체할 수 있습니다. AZ-a와 AZ-b에 동일한 앱 인스턴스가 분산되어 있으므로 한쪽 가용 영역이 장애를 겪어도 트래픽은 다른 쪽으로 흘러갑니다.
핵심 용어
- Well-Architected: AWS가 정리한 설계 모범 사례 프레임워크입니다.
- Stateless: 서버가 클라이언트 상태를 내부에 오래 들고 있지 않는 구조입니다.
- IaC: 인프라를 코드로 표현하는 방식입니다.
- Loose coupling: 컴포넌트를 큐나 API로 느슨하게 연결하는 방식입니다.
- Idempotent: 같은 요청을 반복해도 안전한 성질입니다.
- Circuit Breaker: 외부 호출 실패가 반복되면 일정 시간 호출을 차단하는 패턴입니다.
- RTO: 장애 발생 후 서비스가 복구되기까지 허용하는 최대 시간입니다.
- RPO: 장애 발생 시 허용 가능한 최대 데이터 손실 시간입니다.
Well-Architected 여섯 기둥
2021년부터 AWS Well-Architected Framework는 기존 다섯 기둥에 지속 가능성(Sustainability)을 추가해 여섯 기둥으로 확장되었습니다. 각 기둥은 정답이 아니라 설계 리뷰에서 물어야 할 질문 영역입니다.
| 기둥 | 핵심 질문 | 대표 실천 |
|---|---|---|
| 운영 우수성(Operational Excellence) | 변경과 장애 대응이 반복 가능한가 | IaC, 런북, 배포 파이프라인 |
| 보안(Security) | 최소 권한과 암호화가 기본인가 | IAM 정책, 전송/저장 암호화, 감사 로그 |
| 신뢰성(Reliability) | 장애를 견디고 복구할 수 있는가 | Multi-AZ, 자동 복구, 백업/복원 훈련 |
| 성능 효율성(Performance Efficiency) | 자원을 효율적으로 선택하고 확장하는가 | 적정 인스턴스 선택, 캐싱, CDN |
| 비용 최적화(Cost Optimization) | 불필요한 비용을 구조적으로 줄이는가 | 예약 인스턴스, 태그 정책, 유휴 자원 정리 |
| 지속 가능성(Sustainability) | 환경 영향을 최소화하는가 | 적정 크기 조정, 관리형 서비스 활용, 리전 선택 |
강한 팀은 이 여섯 기둥을 분기마다 점검합니다. 모든 항목을 완벽히 맞추는 것이 목적이 아니라, 지금 우리 시스템이 어떤 축에서 취약한지 드러내는 것이 목적입니다.
Cloud-Native 대 Lift-and-Shift
기존 시스템을 클라우드로 옮기는 방식은 크게 두 가지로 나뉩니다. 각 접근법의 장단점을 이해해야 마이그레이션 전략을 올바르게 세울 수 있습니다.
| 항목 | Lift-and-Shift | Cloud-Native |
|---|---|---|
| 정의 | 기존 서버 구성을 그대로 VM으로 이전 | 클라우드 서비스에 맞게 재설계 |
| 초기 비용 | 낮음 (변경 최소) | 높음 (재작성 필요) |
| 운영 비용 | 높음 (클라우드 이점 미활용) | 낮음 (관리형 서비스 활용) |
| 확장성 | 수직 확장 위주 | 수평 확장 가능 |
| 장애 복원력 | 기존과 동일 | Multi-AZ, 자동 복구 |
| 적합 시점 | 빠른 이전이 목표일 때 | 장기 운영 최적화가 목표일 때 |
실무에서는 한 번에 모두 Cloud-Native로 전환하지 않습니다. Lift-and-Shift로 먼저 이전한 뒤, 트래픽이 많은 서비스부터 단계적으로 재설계하는 것이 일반적입니다.
적용 전후 비교
Before에서는 모놀리식 애플리케이션이 단일 서버 한 대에 묶여 있습니다. 변경이 무섭고, 장애 하나가 전체 장애가 됩니다.
After에서는 Stateless 앱 계층과 Multi-AZ 데이터베이스, IaC 기반 배포를 조합합니다. 구조가 나뉘면 변경과 복구가 모두 안전해집니다.
Design for Failure 체크리스트
클라우드 환경에서는 장애를 예방하는 것이 아니라 장애를 전제하고 설계합니다. 아래 네 가지 패턴은 외부 의존성 호출에서 반드시 적용해야 하는 기본 방어 수단입니다.
| 패턴 | 목적 | 구현 포인트 |
|---|---|---|
| Retry (재시도) | 일시적 장애 극복 | 지수 백오프 + 최대 횟수 제한 |
| Circuit Breaker (차단기) | 연쇄 장애 방지 | 실패율 임계치 초과 시 호출 차단, 일정 시간 후 반개방 |
| Timeout (시간 제한) | 무한 대기 방지 | 연결 타임아웃과 읽기 타임아웃 분리 설정 |
| Fallback (대안 경로) | 서비스 연속성 유지 | 캐시 응답 반환, 기본값 사용, 기능 축소 모드 |
이 네 패턴을 조합하면 외부 서비스 장애가 내 서비스의 전체 장애로 확산되는 것을 막을 수 있습니다. 순서는 Timeout → Retry → Circuit Breaker → Fallback 순으로 적용하는 것이 일반적입니다.
재해 복구(DR) 전략
비즈니스 요구에 따라 복구 목표(RTO/RPO)와 비용의 균형을 맞춰야 합니다. 아래 네 가지 전략은 비용이 낮은 순서대로 정렬되어 있습니다.
| 전략 | RTO | RPO | 비용 | 설명 |
|---|---|---|---|---|
| Backup and Restore | 시간 단위 | 시간 단위 | 최저 | 정기 백업 후 장애 시 복원 |
| Pilot Light | 10분~수십 분 | 분 단위 | 낮음 | 핵심 인프라만 최소 구동, 장애 시 확장 |
| Warm Standby | 분 단위 | 초~분 단위 | 중간 | 축소된 환경이 항상 가동, 장애 시 스케일업 |
| Multi-Site Active/Active | 초 단위 | 거의 0 | 최고 | 두 리전이 동시에 트래픽 처리 |
토이 프로젝트라면 Backup and Restore로 충분합니다. 프로덕션 서비스에서는 SLA에 맞는 전략을 선택하고, 분기마다 실제 복원 훈련을 실시해야 합니다. 백업만 하고 복원을 연습하지 않으면 실제 장애 시 복원 절차에서 실패하는 경우가 흔합니다.
Infrastructure as Code 비교
IaC 도구는 인프라 변경을 코드 리뷰, 버전 관리, 자동 테스트 대상으로 만듭니다. 대표적인 세 도구의 특성을 비교합니다.
| 항목 | Terraform | CloudFormation | Pulumi |
|---|---|---|---|
| 제공사 | HashiCorp | AWS | Pulumi |
| 언어 | HCL (선언적) | JSON/YAML (선언적) | Python/TypeScript/Go 등 (명령적) |
| 멀티 클라우드 | 지원 | AWS 전용 | 지원 |
| 상태 관리 | State 파일 (S3 + DynamoDB 잠금 권장) | AWS 자체 관리 | Pulumi Cloud 또는 자체 백엔드 |
| 학습 곡선 | 중간 | 낮음 (AWS 사용자) | 낮음 (기존 언어 활용) |
| 드리프트 감지 | terraform plan |
드리프트 감지 기능 내장 | pulumi preview |
어떤 도구를 선택하든 핵심 원칙은 동일합니다. 수동 콘솔 변경을 금지하고, 모든 인프라 변경을 코드 → 리뷰 → 적용 파이프라인으로 통과시키는 것입니다.
실습: Terraform 기본 구성 예시
아래는 VPC, EC2, S3를 선언하는 최소 Terraform 코드입니다. 실제 프로덕션에서는 모듈로 분리하지만, 구조를 이해하기 위해 한 파일로 보여 줍니다.
provider "aws" {
region = "ap-northeast-2"
}
# 네트워크 계층
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
enable_dns_hostnames = true
tags = { Name = "demo-vpc" }
}
resource "aws_subnet" "public_a" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
availability_zone = "ap-northeast-2a"
tags = { Name = "public-a" }
}
resource "aws_subnet" "public_b" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.2.0/24"
availability_zone = "ap-northeast-2b"
tags = { Name = "public-b" }
}
# 컴퓨트 계층
resource "aws_instance" "app" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.micro"
subnet_id = aws_subnet.public_a.id
tags = { Name = "demo-app" }
}
# 스토리지 계층
resource "aws_s3_bucket" "assets" {
bucket = "demo-assets-bucket"
tags = { Name = "demo-assets" }
}
resource "aws_s3_bucket_versioning" "assets" {
bucket = aws_s3_bucket.assets.id
versioning_configuration {
status = "Enabled"
}
}이 코드에서 주목할 점은 세 가지입니다. 첫째, 네트워크/컴퓨트/스토리지가 명확히 분리되어 있습니다. 둘째, 두 개의 서브넷이 서로 다른 AZ에 배치되어 가용성을 확보합니다. 셋째, S3 버킷에 버저닝을 활성화해 실수로 삭제해도 복구할 수 있습니다.
Auto Scaling 아키텍처 패턴
Auto Scaling은 트래픽 변화에 따라 인스턴스 수를 자동으로 조절하는 패턴입니다. 이 패턴이 제대로 동작하려면 앱 계층이 반드시 Stateless여야 합니다.
[CloudWatch Alarm: CPU > 70%]
│
▼
[Auto Scaling Group]
├── 최소 인스턴스: 2
├── 최대 인스턴스: 10
├── 희망 인스턴스: 현재 부하에 따라 자동 결정
└── 쿨다운: 300초
│
▼
[새 인스턴스 시작] → [ALB 타겟 그룹 등록] → [헬스 체크 통과] → [트래픽 수신]Auto Scaling 정책을 설계할 때 흔히 놓치는 부분은 스케일 인(축소) 정책입니다. 스케일 아웃(확장)만 설정하면 트래픽이 줄어도 인스턴스가 유지되어 비용이 낭비됩니다. 스케일 인 임계값은 스케일 아웃 임계값보다 충분히 낮게 설정해 진동(flapping)을 방지합니다.
Python 헬스 체크 엔드포인트 예시
ALB가 인스턴스의 정상 여부를 판단하려면 헬스 체크 엔드포인트가 필요합니다. 단순히 200을 반환하는 것이 아니라, 핵심 의존성의 상태까지 확인하는 것이 좋습니다.
from fastapi import FastAPI, status
from fastapi.responses import JSONResponse
import asyncpg
import redis.asyncio as redis
app = FastAPI()
DATABASE_URL = "postgresql://user:pass@db-host:5432/mydb"
REDIS_URL = "redis://cache-host:6379/0"
@app.get("/health")
async def health_check():
"""ALB 타겟 그룹 헬스 체크용 엔드포인트."""
checks = {}
# DB 연결 확인
try:
conn = await asyncpg.connect(DATABASE_URL)
await conn.execute("SELECT 1")
await conn.close()
checks["database"] = "ok"
except Exception:
checks["database"] = "fail"
# 캐시 연결 확인
try:
r = redis.from_url(REDIS_URL)
await r.ping()
await r.aclose()
checks["cache"] = "ok"
except Exception:
checks["cache"] = "fail"
all_healthy = all(v == "ok" for v in checks.values())
status_code = status.HTTP_200_OK if all_healthy else status.HTTP_503_SERVICE_UNAVAILABLE
return JSONResponse(
content={"status": "healthy" if all_healthy else "degraded", "checks": checks},
status_code=status_code,
)이 엔드포인트는 DB와 캐시 연결을 모두 확인합니다. 하나라도 실패하면 503을 반환하므로 ALB가 해당 인스턴스로 트래픽을 보내지 않습니다. 프로덕션에서는 연결 풀을 재사용하고, 타임아웃을 짧게(2-3초) 설정해 헬스 체크 자체가 느려지지 않도록 해야 합니다.
Architecture Decision Record (ADR) 템플릿
아키텍처 결정은 시간이 지나면 맥락이 사라집니다. ADR은 "왜 이 결정을 했는가"를 기록해 미래의 팀원이 동일한 논의를 반복하지 않도록 돕습니다.
# ADR-001: 데이터베이스 Multi-AZ 구성 채택
## 상태
승인됨 (2026-01-15)
## 맥락
서비스 SLA 99.9%를 충족하려면 DB 단일 장애 지점을 제거해야 합니다.
Single-AZ RDS에서 AZ 장애 발생 시 복구에 30분 이상 소요된 사례가 있었습니다.
## 결정
RDS PostgreSQL을 Multi-AZ 배포로 전환합니다.
비용은 약 2배 증가하지만, 자동 장애 조치로 RTO를 1-2분으로 단축합니다.
## 결과
- 월 비용 약 $200 증가
- RTO: 30분 → 2분 이내
- 수동 개입 없이 자동 페일오버 가능
- 분기별 페일오버 훈련을 운영 일정에 추가ADR은 복잡할 필요가 없습니다. 맥락(왜), 결정(무엇), 결과(그래서)만 기록하면 됩니다. Git 저장소의 docs/adr/ 디렉터리에 번호를 붙여 관리하는 것이 일반적입니다.
멀티클라우드 비교와 마이그레이션 체크리스트
| 항목 | 단일 클라우드 | 멀티클라우드 |
|---|---|---|
| 초기 구축 속도 | 빠름 | 느림 |
| 운영 복잡도 | 중간 | 높음 |
| 공급사 장애 분산 | 제한적 | 높음 |
| 기술 표준화 필요성 | 보통 | 매우 높음 |
| 인력 요구 | 보통 | 높음 |
| 단계 | 확인 항목 |
|---|---|
| 발견(Discover) | 현재 자산, 의존성, 데이터 흐름 목록화 |
| 분류(Assess) | Rehost/Replatform/Refactor 대상 분류 |
| 설계(Design) | 네트워크, IAM, 관측, 백업 표준 정의 |
| 이전(Migrate) | 파일럿 워크로드로 절차 검증 |
| 안정화(Operate) | 비용/성능/보안 지표 기반 개선 루프 |
실습: 다층 웹 아키텍처 의사 코드
1단계 -- IaC 골조
def vpc(): return {"cidr": "10.0.0.0/16", "azs": 2}
def subnets(): return ["public-a", "public-b", "private-a", "private-b"]2단계 -- 컴퓨트
def asg(min_, max_): return {"min": min_, "max": max_, "policy": "cpu>60"}3단계 -- 데이터
def rds(): return {"engine": "postgres", "multi_az": True, "backup_days": 7}
def cache(): return {"engine": "redis", "nodes": 2}4단계 -- 객체와 큐
def s3(): return {"versioning": True, "lifecycle": "to-glacier-90d"}
def queue(): return {"visibility_timeout": 30, "dlq": True}5단계 -- 라우팅
def alb(): return {"listeners": [{"port": 443, "tls": True}], "target": "asg"}이 코드는 실제 Terraform이 아니지만, 클라우드 아키텍처를 어떤 식으로 계층별로 생각해야 하는지 잘 보여 줍니다. 네트워크, 컴퓨트, 데이터, 비동기 처리, 라우팅이 각각 분리되어 있어야 구조를 바꾸거나 검증하기 쉬워집니다.
이 코드에서 먼저 봐야 할 점
- Multi-AZ는 선택 기능이 아니라 기본 전제에 가깝습니다.
- DLQ는 재시도 실패를 흡수하는 안전망입니다.
- ASG를 제대로 쓰려면 앱이 Stateless해야 합니다.
이 설계를 실제로 검증하는 순서
아키텍처 글에서는 코드가 실행되느냐만큼 설계 질문에 답할 수 있느냐가 중요합니다. 각 계층을 따로 읽지 말고 "이 구조가 장애, 변경, 복구에 어떤 행동을 가능하게 하는가"를 기준으로 검토해 보세요.
Expected output:
- 앱 계층을 늘려도 세션이나 상태가 깨지지 않는다는 설명이 가능해야 합니다.
- 데이터 계층에서 어떤 자원이 Multi-AZ인지, 어떤 자원이 백업과 복원을 맡는지 구분할 수 있어야 합니다.
- 큐와 DLQ를 둔 이유를 "재시도 실패를 격리하기 위해서"라고 설명할 수 있어야 합니다.
설계 리뷰에서 먼저 물을 질문
- 이 구조에서 단일 실패 지점은 어디에 남아 있는가.
- 수동 변경이 개입되는 구간은 어디이며, IaC로 어떻게 줄일 수 있는가.
- 비용 최적화와 신뢰성 최적화가 충돌할 때 어떤 원칙으로 우선순위를 정할 것인가.
자주 하는 실수 5가지
- 상태를 내부 메모리에 둔 앱을 그대로 수평 확장하려고 합니다.
- 데이터베이스를 Single-AZ로 운영합니다.
- IaC 없이 수동 변경에 의존합니다.
- 외부 호출에 재시도를 넣지 않습니다.
- 백업은 하지만 복구 연습을 하지 않습니다.
실무에서는 이렇게 생각합니다
- Well-Architected는 체크리스트보다 대화 도구에 가깝습니다.
- 모든 품질 중에서도 변경 안전성이 특히 중요합니다.
- 백업보다 복원 훈련이 더 현실적인 검증입니다.
- 작게 시작하고 필요할 때 모듈화하는 편이 낫습니다.
- 문서와 런북도 코드와 함께 출하되어야 합니다.
- ADR로 결정 맥락을 남겨야 6개월 후에도 "왜"를 알 수 있습니다.
체크리스트
- Multi-AZ 구성이 적용되어 있는가.
- IaC로 환경을 재현할 수 있는가.
- 복원 훈련 일정이 있는가.
- 6대 기둥 기준 점검을 분기마다 하는가.
- Design for Failure 패턴(retry, circuit breaker, timeout, fallback)이 적용되어 있는가.
- 헬스 체크 엔드포인트가 핵심 의존성까지 확인하는가.
- ADR로 주요 아키텍처 결정을 기록하고 있는가.
연습 문제
- Well-Architected의 여섯 기둥을 모두 적어 보세요.
- 애플리케이션을 Stateless하게 만드는 대표 기법 하나를 설명해 보세요.
- IaC가 수동 변경보다 안전한 이유를 한 줄로 적어 보세요.
- Backup and Restore 전략과 Warm Standby 전략의 RTO 차이를 설명해 보세요.
- Circuit Breaker 패턴이 필요한 상황을 한 가지 예로 들어 보세요.
처음 질문으로 돌아가기
- Well-Architected의 여섯 기둥은 각각 무엇을 보라고 말할까요?
- 운영 우수성은 변경과 대응 절차의 반복 가능성을, 보안은 최소 권한과 암호화를, 신뢰성은 장애 대응과 복구를, 성능 효율성은 자원 선택과 확장 전략을, 비용 최적화는 낭비를 줄이는 구조를, 지속 가능성은 환경 영향 최소화를 봅니다.
- 기본적인 다층 웹 아키텍처는 어떤 모습일까요?
- CDN → ALB → Stateless App(Multi-AZ) → Cache/DB/Object Storage로 계층이 분리되고, 각 계층이 독립적으로 확장 가능한 구조입니다.
- Stateless와 Stateful을 왜 분리해야 할까요?
- Stateless 계층은 인스턴스를 자유롭게 추가/제거할 수 있어 수평 확장이 가능합니다. 상태를 DB나 캐시 같은 전용 계층에 위임해야 Auto Scaling이 안전하게 동작합니다.
정리 및 다음 단계
여기까지가 Cloud Computing 101의 마무리입니다. 이제 클라우드를 하나의 서비스 목록이 아니라, 운영/보안/신뢰성/성능/비용/지속 가능성을 함께 조립하는 설계 문제로 볼 수 있어야 합니다. 다음 시리즈에서는 Containers 101, Kubernetes 101, Serverless 101처럼 더 구체적인 실행 추상화로 들어가게 됩니다.
각 아키텍처 원칙을 처음부터 모두 구현할 필요는 없습니다. 서비스가 성장하고 문제가 드러나면서 단계적으로 개선하는 것이 현실적입니다. 토이 프로젝트는 단일 VM도 충분할 수 있습니다. 팀이 성장하고 트래픽이 증가하면 그때 Multi-AZ, 로드 밸런싱, 캐싱을 추가합니다.
아키텍처는 비즈니스 요구사항, 팀 역량, 예산 제약을 모두 고려해야 합니다. 기술적으로 완벽하지만 유지보수 불가능한 설계는 실무에서 실패합니다.
시리즈 목차
- Cloud Computing 101 (1/10): Cloud Computing이란 무엇인가?
- Cloud Computing 101 (2/10): IaaS, PaaS, SaaS
- Cloud Computing 101 (3/10): Region과 Availability Zone
- Cloud Computing 101 (4/10): Compute
- Cloud Computing 101 (5/10): Storage
- Cloud Computing 101 (6/10): Network
- Cloud Computing 101 (7/10): Identity와 Security
- Cloud Computing 101 (8/10): Monitoring
- Cloud Computing 101 (9/10): Cost Management
- Cloud Architecture 기초 (현재 글)
참고 자료
'Software Engineering' 카테고리의 다른 글
| Cloud Computing 101 (9/10): Cost Management (0) | 2026.06.16 |
|---|---|
| Cloud Computing 101 (8/10): Monitoring (0) | 2026.06.16 |
| Cloud Computing 101 (7/10): Identity와 Security (0) | 2026.06.16 |
| Cloud Computing 101 (6/10): Network (0) | 2026.06.16 |
| Cloud Computing 101 (5/10): Storage (3) | 2026.06.08 |
- Total
- Today
- Yesterday
- Tool Use
- ai agent
- DevOps
- AZURE
- QUALITY
- backend
- Agent
- softwaredesign
- reliability
- embeddings
- LLM
- testing
- openAI
- Computer Science
- Production
- frontend
- Cloud
- APIDesign
- docker
- containers
- vector search
- Architecture
- Ai
- langchain
- Python
- rag
- Kubernetes
- http
- DesignPatterns
- webdevelopment
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |