

티스토리 뷰
RAG를 붙이면 팀은 종종 안도합니다. 적어도 외부 지식을 붙였으니 환각이 줄겠지라고 기대하기 때문입니다. 하지만 운영에 들어가면 전혀 다른 종류의 오류가 생깁니다. 검색이 엉뚱한 문서를 가져오거나, 올바른 문서를 가져왔는데도 모델이 무시하고 상상으로 답하는 식입니다.
이때 종단 점수 하나만 보고 있으면 문제를 거의 고칠 수 없습니다. 답이 틀렸다는 사실은 알 수 있어도 검색이 망가졌는지, 생성이 망가졌는지, 아니면 둘 다 흔들리는지 알 수 없기 때문입니다.
현업에서 저는 RAG를 운영하면서 faithfulness를 보지 않는 팀이 가장 위험하다고 느꼈습니다. 그럴듯하게 틀린 답이 사용자에게 가장 설득력 있게 전달되기 때문입니다. 검색 품질이 좋다는 사실만으로는 안심할 수 없습니다.
이 글은 AI Evaluation 101 시리즈의 6번째 글입니다.
여기서는 Context Recall, Context Precision, Faithfulness, Answer Relevance 네 지표로 RAG를 어떻게 단계별로 진단할지 정리하겠습니다.
이 글에서 다룰 문제
- RAG를 한 개 모델이 아니라 두 단계 파이프라인으로 봐야 하는 이유는 무엇일까요?
- Context Recall과 Context Precision은 검색 단계의 어떤 실패를 각각 드러낼까요?
- Faithfulness는 왜 운영 RAG에서 가장 우선순위가 높은 지표일까요?
- Answer Relevance가 낮으면 검색이 아니라 프롬프트나 생성 단계 문제일 수 있다는 뜻은 무엇일까요?
- 네 지표를 함께 보면 어떤 고장 원인을 빠르게 진단할 수 있을까요?
왜 이 글이 중요한가
RAG는 검색과 생성이 분리되어 있기 때문에, 점검도 두 층으로 나뉘어야 합니다. 검색이 잘못되면 생성은 성실하게도 잘못된 근거를 바탕으로 답을 만듭니다. 반대로 검색은 맞았는데 생성이 컨텍스트를 무시해도 결과는 비슷하게 나빠 보입니다.
이 차이를 분리하지 않으면 팀은 틀린 곳을 고칩니다. 검색 인덱스를 다시 만들었는데 사실은 프롬프트가 컨텍스트 준수 규칙을 약하게 강제하고 있었던 경우가 대표적입니다.
따라서 RAG 평가는 단순 품질 측정이 아니라 장애 분해 도구입니다. 네 개 지표가 있어야 비로소 '무엇이 고장 났는가'에 답할 수 있습니다.
RAG 평가를 이해하는 가장 좋은 방법: 답변 품질이 아니라 파이프라인 진단으로 보는 것입니다
이 주제는 개별 기법을 외우기보다 먼저 어떤 운영 문제를 풀기 위한 장치인지 붙잡아 두는 편이 이해가 빠릅니다. RAG는 검색과 생성이 분리되어 있기 때문에, 점검도 두 층으로 나뉘어야 합니다. 검색이 잘못되면 생성은 성실하게도 잘못된 근거를 바탕으로 답을 만듭니다. 반대로 검색은 맞았는데 생성이 컨텍스트를 무시해도 결과는 비슷하게 나빠 보입니다.
RAG는 하나의 모델이 아니라 검색과 생성이 연결된 파이프라인입니다. 그래서 평가도 '정답률 하나'로 끝내지 말고, 어느 단계가 망가졌는지 분리해서 봐야 합니다.
이 관점을 먼저 잡아 두면 뒤에 나오는 코드와 지표를 기능 설명이 아니라 운영 설계 관점에서 읽을 수 있습니다. 결국 중요한 것은 수치 이름보다, 그 수치가 어떤 의사결정을 가능하게 하느냐입니다.
핵심 개념

RAG는 단일 모델이 아니라 파이프라인입니다
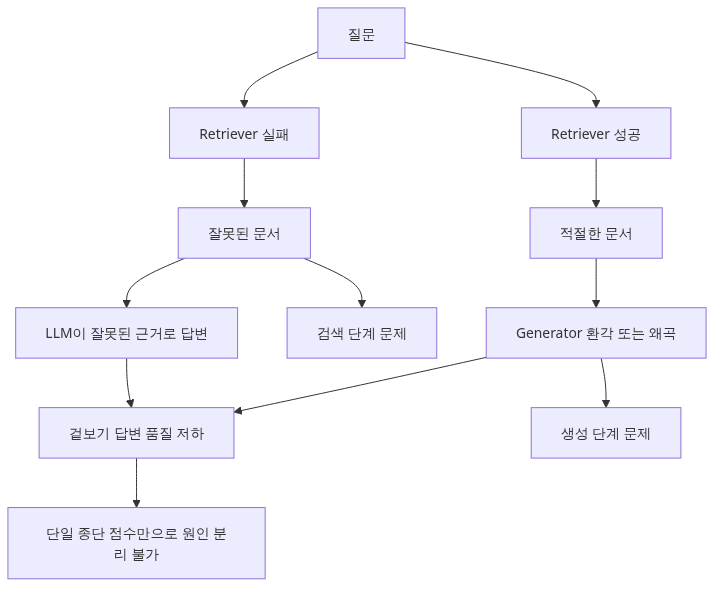
RAG(Retrieval-Augmented Generation)는 두 단계로 동작합니다.
question → [1. Retriever] → top-K documents → [2. Generator (LLM)] → answer
(vector DB) (uses context)이 두 단계는 각각 따로 망가질 수 있습니다.
- Retriever가 잘못된 문서를 가져오면 → LLM은 잘못된 context로 답변 (생성은 정상)
- Retriever가 올바른 문서를 가져왔는데 LLM이 무시하거나 hallucinate → 생성 단계가 문제
따라서 RAG 평가는 단계별로 따로 측정해야 합니다. "답변 정확도 70%"라는 단일 숫자는 어디가 망가졌는지 알려주지 않습니다.
RAG 4대 메트릭

업계 표준은 다음 4가지입니다 (RAGAS, TruLens 등이 채택).
| 단계 | 메트릭 | 무엇을 묻는가 |
|---|---|---|
| Retrieval | Context Recall | 정답에 필요한 정보가 검색된 문서에 있는가 |
| Retrieval | Context Precision | 검색된 문서가 모두 관련 있는가 (노이즈 비율) |
| Generation | Faithfulness | 답변이 검색된 context에만 근거하는가 (hallucination 여부) |
| Generation | Answer Relevance | 답변이 질문에 실제로 답하는가 |
각각을 살펴봅니다.
Retrieval 평가

Context Recall — 필요한 정보가 검색됐는가
정답을 만들 때 반드시 알아야 하는 사실(claim)들이 검색된 context에 모두 있는지 확인합니다.
# rag/context_recall.py
from openai import OpenAI
import json
client = OpenAI()
RECALL_PROMPT = """Check whether every fact (claim) needed to produce the reference is present in the retrieved context.
Question: {question}
Reference answer: {reference}
Retrieved context:
{context}
First, decompose the reference into atomic claims. Then mark each claim as supported by the context (yes/no).
Output JSON:
{{
"claims": [
{{"claim": "...", "supported_by_context": true}},
...
]
}}
"""
def context_recall(question: str, reference: str, context: str) -> float:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": RECALL_PROMPT.format(
question=question, reference=reference, context=context
)}],
temperature=0,
response_format={"type": "json_object"},
)
data = json.loads(response.choices[0].message.content)
claims = data["claims"]
if not claims:
return 0.0
supported = sum(1 for c in claims if c["supported_by_context"])
return supported / len(claims)해석: 0.8 = 정답의 80% 정보가 검색됨. 0.5 미만이면 retriever가 핵심 문서를 놓치고 있습니다.
Context Precision — 검색된 문서가 노이즈인가
검색된 context 중 실제로 관련 있는 비율입니다. Top-K=10인데 그중 2개만 관련 있으면 precision=0.2입니다.
# rag/context_precision.py
PRECISION_PROMPT = """Is the following retrieved chunk needed to answer the question?
Question: {question}
Chunk: {chunk}
Output JSON: {{"relevant": true/false}}
"""
def context_precision(question: str, chunks: list[str]) -> float:
relevant_count = 0
for chunk in chunks:
response = client.chat.completions.create(
model="gpt-4o-mini", # cheap model is fine for binary judgment
messages=[{"role": "user", "content": PRECISION_PROMPT.format(
question=question, chunk=chunk
)}],
temperature=0,
response_format={"type": "json_object"},
)
if json.loads(response.choices[0].message.content)["relevant"]:
relevant_count += 1
return relevant_count / len(chunks)해석: precision이 낮으면 LLM이 노이즈에 휩쓸려 잘못된 답변을 생성할 위험이 큽니다.
Generation 평가

Faithfulness — Hallucination 탐지
답변의 모든 주장이 검색된 context로 뒷받침되는지 확인합니다. Context에 없는 사실을 말하면 hallucination입니다.
# rag/faithfulness.py
FAITHFULNESS_PROMPT = """Decompose the answer into atomic claims and check whether each is supported by the context.
Question: {question}
Context: {context}
Answer: {answer}
Output JSON:
{{
"claims": [
{{"claim": "...", "supported_by_context": true/false}},
...
]
}}
"""
def faithfulness(question: str, context: str, answer: str) -> float:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": FAITHFULNESS_PROMPT.format(
question=question, context=context, answer=answer
)}],
temperature=0,
response_format={"type": "json_object"},
)
data = json.loads(response.choices[0].message.content)
claims = data["claims"]
if not claims:
return 0.0
supported = sum(1 for c in claims if c["supported_by_context"])
return supported / len(claims)해석: 1.0 = 모든 주장이 context로 뒷받침됨. 0.7 미만이면 hallucination이 심각합니다. production RAG의 최우선 metric입니다.
Answer Relevance — 질문에 진짜 답했는가
LLM은 가끔 질문과 무관한 내용을 답합니다. 답변에서 역으로 질문을 생성해 원 질문과의 유사도를 봅니다.
# rag/answer_relevance.py
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
REVERSE_PROMPT = """Guess three questions that this answer would be a response to. One per line.
Answer: {answer}
"""
def answer_relevance(question: str, answer: str) -> float:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": REVERSE_PROMPT.format(answer=answer)}],
temperature=0,
)
generated_qs = response.choices[0].message.content.strip().split("\n")[:3]
emb_orig = model.encode([question])[0]
embs_gen = model.encode(generated_qs)
sims = [np.dot(emb_orig, eg) / (np.linalg.norm(emb_orig) * np.linalg.norm(eg))
for eg in embs_gen]
return float(np.mean(sims))해석: 1.0 = 답변이 정확히 그 질문에 대한 답. 0.6 미만이면 답변이 질문과 어긋남.
4개 메트릭으로 진단하기
4개 메트릭을 함께 보면 어디가 망가졌는지 진단할 수 있습니다.
| Recall | Precision | Faithfulness | Relevance | 진단 |
|---|---|---|---|---|
| Low | High | High | High | Retriever가 핵심 문서를 놓침 → embedding 또는 chunking 개선 |
| High | Low | High | High | Retriever가 노이즈 너무 많이 가져옴 → top-K 줄이거나 reranker 추가 |
| High | High | Low | High | LLM이 hallucinate → prompt에 "context에만 근거" 명시 |
| High | High | High | Low | LLM이 질문 무시 → prompt 재설계 |
| High | High | High | High | RAG가 잘 동작 |
이 진단표 없이 "답변 정확도가 70%"라는 단일 숫자만 보면 무엇을 고쳐야 할지 알 수 없습니다.
RAGAS — 위 4개를 묶어서 자동화
위 4개 metric을 직접 구현할 수도 있지만, RAGAS 라이브러리가 표준 구현을 제공합니다.
# rag/with_ragas.py
from ragas import evaluate
from ragas.metrics import (
context_recall, context_precision,
faithfulness, answer_relevancy,
)
from datasets import Dataset
dataset = Dataset.from_dict({
"question": ["What is RAG?", ...],
"ground_truth": ["RAG combines retrieval with generation...", ...],
"answer": ["RAG is a retrieval-based generation technique...", ...],
"contexts": [["RAG is...", "Retrieval is..."], ...],
})
result = evaluate(
dataset,
metrics=[context_recall, context_precision, faithfulness, answer_relevancy],
)
print(result)
# {'context_recall': 0.85, 'context_precision': 0.72, 'faithfulness': 0.91, 'answer_relevancy': 0.88}직접 구현할 시간이 없으면 RAGAS로 시작하세요. 단, 도메인 특화 평가가 필요하면 직접 구현이 더 정확합니다.
이 코드에서 먼저 봐야 할 점
- 텍스트로 그린 두 단계 파이프라인부터 보시면 좋습니다. 이 그림이 이후 네 지표를 왜 둘씩 나눠 보는지 설명해 줍니다.
- Faithfulness 예제는 운영 우선순위가 왜 높은지 가장 잘 드러냅니다. 검색된 문맥에 없는 주장을 답변이 만들어 냈는지 바로 볼 수 있습니다.
- 네 지표 진단 표는 실무에서 바로 쓰입니다. 점수 조합만으로 검색, 노이즈, 환각, 오프토픽 문제를 거의 즉시 분류할 수 있습니다.
이 세 지점을 먼저 읽고 나면 세부 구현과 지표 해석이 훨씬 빨라집니다. 코드가 길어 보여도 운영 질문은 대개 여기로 다시 돌아옵니다.
어디서 자주 헷갈릴까요?
Mistake 1: 답변 정확도만 측정
"답변 70% 맞음"이라는 단일 숫자는 무엇이 망가졌는지 알려주지 않습니다. 반드시 4개 metric을 분리해서 측정하세요.
Mistake 2: Retrieval만 보고 만족
Recall=0.95, Precision=0.9면 retriever가 좋다고 끝내면 안 됩니다. Faithfulness가 0.5면 LLM이 hallucinate하고 있어서 RAG는 여전히 망가진 상태입니다.
Mistake 3: Faithfulness 무시
Production RAG의 최대 위험은 그럴듯한 거짓입니다. Faithfulness 점수를 production alert에 연결하세요. 0.8 미만이면 즉시 조사.
Mistake 4: Top-K를 무작정 늘림
"더 많은 context = 더 좋은 답"이 아닙니다. K=20이 되면 precision이 떨어지고 LLM이 혼란스러워집니다. K=3~5에서 시작해서 실험으로 최적값을 찾으세요.
Mistake 5: Ground truth context 없이 Recall 측정
Context Recall은 reference 답변이 필요합니다. Reference 없이는 측정 불가입니다. 평가 데이터셋에 reference answer를 반드시 포함하세요 (Ep2 참조).
현업에서 제가 가장 자주 보는 문제는 결과 숫자만 보고 원인 분해를 건너뛰는 습관입니다. 평가가 개선을 돕지 못하고 보고서용 숫자로만 남는 순간, 팀은 다시 감각에 의존하게 됩니다.
첫 번째 운영 체크리스트
- 검색 단계와 생성 단계를 별도 지표로 분리했는가
- Faithfulness 하락을 별도 경보로 취급하는가
- top-K를 늘리기 전에 Precision 하락을 먼저 보는가
- Reference answer가 포함된 평가셋을 준비했는가
- 하나의 종단 점수로 RAG 상태를 단순화하지 않는가
실무에서는 이렇게 생각한다
실무에서는 Recall과 Precision을 함께 봐야 retriever를 고칠지 reranker를 붙일지 결정할 수 있습니다. 하나만 보면 어디가 비어 있는지 감이 잘 오지 않습니다.
또한 Faithfulness는 단순 품질 수치가 아니라 신뢰 지표입니다. 특히 문서 기반 지원 도구나 사내 지식 검색에서는 사실과 다른 답이 그럴듯하게 나오는 순간 팀 신뢰가 급격히 떨어집니다.
다음 글의 에이전트 평가로 넘어가면, 이제 한 번의 답변이 아니라 여러 단계 실행을 평가해야 합니다. RAG에서 단계 분해를 익혀 두면 에이전트 평가도 훨씬 자연스럽게 이해됩니다.
정리: RAG 평가는 검색과 생성의 책임을 갈라서 봐야 제대로 고칠 수 있습니다
- RAG는 retrieval + generation 두 단계 파이프라인이고, 각각 따로 측정해야 합니다.
- 4대 메트릭: Context Recall (검색 누락), Context Precision (노이즈), Faithfulness (hallucination), Answer Relevance (질문 적중).
- 4개 메트릭의 조합으로 어디가 망가졌는지 진단할 수 있습니다.
- Faithfulness는 production에서 가장 중요한 metric입니다. Hallucination을 잡습니다.
- 직접 구현 대신 RAGAS를 쓰면 빠르게 시작할 수 있습니다.
다음 글에서는 단일 응답이 아닌 agent의 trajectory를 평가하는 법을 다룹니다.
이제 단일 응답을 넘어서, 여러 단계 실행을 거치는 에이전트 평가로 넘어갑니다. 어디서 잘못됐는지 분해해서 보는 감각은 다음 글에서 더 중요해집니다.
운영 체크리스트
- Context Recall, Precision, Faithfulness, Relevance를 함께 기록하기
- Faithfulness 하락을 즉시 조사하기
- top-K 확대 전에 노이즈 증가 여부를 검토하기
- 평가셋에 reference answer를 포함시키기
- RAGAS 같은 표준 도구로 시작하되 도메인별 커스텀 지표를 준비하기
AI Evaluation 101 시리즈
- 왜 LLM 애플리케이션을 평가해야 하는가
- 평가 데이터셋 설계하기
- 결정적 지표 — Exact Match, BLEU, ROUGE
- LLM-as-Judge — 모델로 모델을 평가하기
- Rubric 기반 채점 설계
- RAG 시스템 평가하기 (현재 글)
- 에이전트 평가하기 — 단일 응답이 아닌 trajectory (예정)
- 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (예정)
- LLM A/B 테스팅 — 어느 prompt가 더 나은가 (예정)
- 운영 환경에서의 지속적 평가 (예정)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| AI Evaluation 101 : 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (0) | 2026.05.18 |
|---|---|
| AI Evaluation 101 : 에이전트 평가하기 — 단일 응답이 아닌 trajectory (0) | 2026.05.18 |
| AI Evaluation 101 : Rubric 기반 채점 설계 (0) | 2026.05.18 |
| AI Evaluation 101 : LLM-as-Judge — 모델로 모델을 평가하기 (0) | 2026.05.18 |
| AI Evaluation 101 : 결정적 지표 — Exact Match, BLEU, ROUGE (0) | 2026.05.18 |
- Total
- Today
- Yesterday
- Cloud
- harness
- rag
- AI Evaluation
- embeddings
- LLM
- softwaredesign
- serverless
- Architecture
- reliability
- Prompt engineering
- AZURE
- Agent
- Computer Science
- Cleancode
- langchain
- DesignPatterns
- backend
- APIDesign
- Python
- Production
- openAI
- ai safety
- Azure Functions
- DevOps
- Tool Use
- http
- Refactoring
- ai agent
- vector search
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |