

티스토리 뷰
에이전트를 붙인 팀이 가장 자주 하는 착각은 최종 답만 맞으면 된다고 믿는 것입니다. 하지만 실제 운영에서는 중간 과정이 비용, 지연, 보안, 실패율을 모두 바꿉니다. 정답 하나를 얻기 위해 도구를 열두 번 호출하는 에이전트는 같은 답을 네 단계에 끝내는 에이전트와 전혀 다른 시스템입니다.
또한 에이전트는 실패 양상도 다릅니다. 도구를 잘못 고르거나, 맞는 도구를 골라도 인자를 틀리게 넣거나, 중간 실패 후 회복하지 못하고 멈춰 버립니다. 이런 문제는 최종 문장만 읽어서는 잘 보이지 않습니다.
현업에서 저는 '결과는 맞았는데 왜 이렇게 비싸지?'라는 질문이 결국 trajectory를 보면서 풀리는 경우를 많이 봤습니다. 같은 작업을 두 배, 세 배 단계로 수행하면 비용과 지연이 빠르게 폭증합니다.
이 글은 AI Evaluation 101 시리즈의 7번째 글입니다.
여기서는 task success, tool selection, tool arguments, trajectory efficiency, recovery를 함께 보면서 에이전트를 어떻게 평가해야 하는지 정리하겠습니다.
이 글에서 다룰 문제
- 에이전트 평가는 왜 단일 응답 평가와 완전히 다른 관점을 요구할까요?
- end-to-end 성공률과 step-level 분석은 어떤 역할 분담으로 함께 써야 할까요?
- 도구 선택 오류를 confusion matrix로 보면 무엇이 명확해질까요?
- step overhead가 비용과 지연 문제를 어떻게 드러낼까요?
- 복구 평가를 하지 않으면 운영에서 어떤 종류의 장애를 놓치게 될까요?
왜 이 글이 중요한가
에이전트는 정답 품질뿐 아니라 실행 비용과 실패 복원력까지 함께 관리해야 합니다. 최종 답이 맞아도 잘못된 메일을 다섯 번 보내고 여섯 번째에 맞춘 시스템은 운영 불가능합니다.
특히 도구 호출이 포함된 워크플로에서는 중간 단계가 곧 리스크입니다. 잘못된 API 호출, 과도한 재시도, 실패 후 포기 패턴은 전부 사용자 경험과 비용에 직접 연결됩니다.
그래서 에이전트 평가는 더 넓은 운영 계기판이 필요합니다. 정답률만 높다고 배포할 수 없고, trajectory 전체가 합리적인지까지 확인해야 합니다.
에이전트 평가를 이해하는 가장 좋은 방법: 답이 아니라 실행 궤적을 보는 것입니다
이 주제는 개별 기법을 외우기보다 먼저 어떤 운영 문제를 풀기 위한 장치인지 붙잡아 두는 편이 이해가 빠릅니다. 에이전트는 정답 품질뿐 아니라 실행 비용과 실패 복원력까지 함께 관리해야 합니다. 최종 답이 맞아도 잘못된 메일을 다섯 번 보내고 여섯 번째에 맞춘 시스템은 운영 불가능합니다.
에이전트는 한 번 답하고 끝나는 시스템이 아닙니다. 어떤 도구를 어떤 순서로 몇 번 호출했고, 실패를 어떻게 복구했는지까지 포함한 실행 궤적 전체가 품질의 일부입니다.
이 관점을 먼저 잡아 두면 뒤에 나오는 코드와 지표를 기능 설명이 아니라 운영 설계 관점에서 읽을 수 있습니다. 결국 중요한 것은 수치 이름보다, 그 수치가 어떤 의사결정을 가능하게 하느냐입니다.
핵심 개념

Agent 평가는 왜 다른가

지금까지(Ep1~Ep6)는 단일 응답 평가였습니다. 질문 → 답변 한 쌍을 채점합니다.
Agent는 다릅니다. Agent는 여러 단계를 거쳐 작업을 완료합니다.
User: "Email me a summary of this week's schedule"
↓
Step 1: read_calendar() → [10 meetings]
Step 2: read_emails() → [3 emails]
Step 3: summarize(...) → "This week's summary: ..."
Step 4: send_email(...) → "sent"
↓
Final reply: "Done, I sent the email."Agent 평가는 최종 답변만 보면 안 됩니다. 다음 5가지를 함께 측정해야 합니다.
- Task success — 사용자가 원한 결과가 나왔는가
- Tool selection — 올바른 tool을 호출했는가
- Tool arguments — tool 인자가 올바른가
- Trajectory efficiency — 불필요한 단계 없이 최단 경로로 갔는가
- Recovery — 도중 실패에서 복구했는가
각각을 살펴봅니다.
평가의 두 층위 — End-to-end vs Step-level
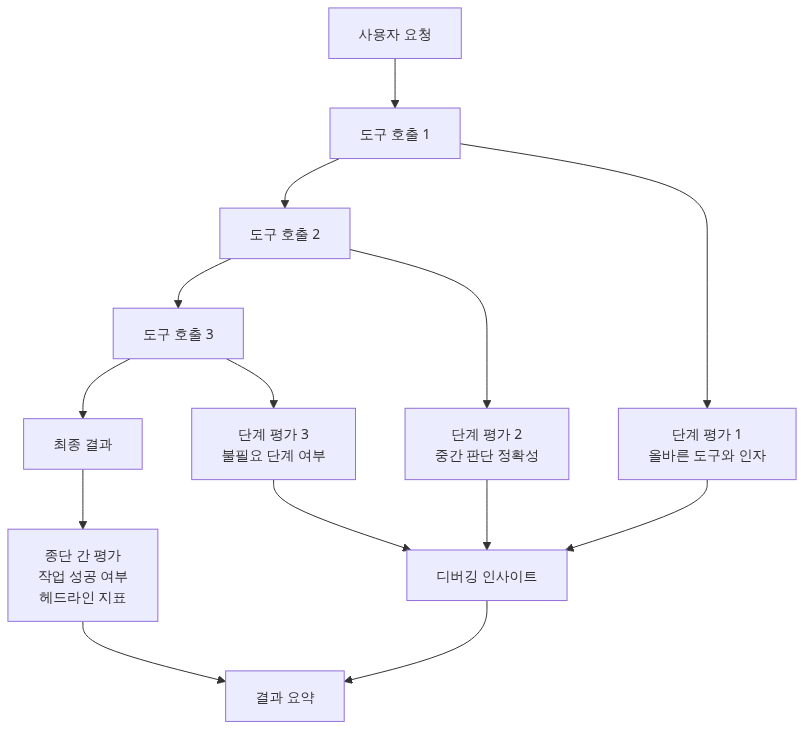
Agent 평가에는 두 가지 시점이 있습니다.
End-to-end (전체 결과)
최종 결과만 봅니다. "이메일이 실제로 보내졌는가?" 하나만 묻습니다.
# agent_eval/end_to_end.py
def end_to_end_success(agent_run: dict) -> bool:
return agent_run["final_state"]["email_sent"] is True장점: 단순합니다. 사용자 가치와 직결됩니다.
단점: 실패해도 어디서 망가졌는지 모릅니다.
Step-level (단계별)
각 step에서 올바른 tool을 올바른 인자로 호출했는가를 봅니다.
# agent_eval/step_level.py
expected_trajectory = [
{"tool": "read_calendar", "args_match": lambda a: "week" in a.get("range", "")},
{"tool": "read_emails", "args_match": lambda a: a.get("limit", 0) <= 10},
{"tool": "summarize", "args_match": lambda a: True},
{"tool": "send_email", "args_match": lambda a: "@" in a.get("to", "")},
]
def step_match_score(actual: list[dict], expected: list[dict]) -> float:
matches = 0
for i, exp in enumerate(expected):
if i >= len(actual):
break
a = actual[i]
if a["tool"] == exp["tool"] and exp["args_match"](a["args"]):
matches += 1
return matches / len(expected)장점: 어느 step이 망가졌는지 정확히 가리킵니다.
단점: 정답 trajectory가 여러 개일 수 있어 너무 엄격하면 false negative.
실무 권장: end-to-end로 큰 그림을 보고, 실패 케이스만 step-level로 분석.
Tool Selection 평가 — Confusion Matrix

Agent가 tool을 잘못 고르는 경우는 흔합니다. "send_email" 대신 "draft_email"을 부르는 식입니다. Tool selection을 분류 문제로 보고 confusion matrix를 만듭니다.
# agent_eval/tool_confusion.py
from sklearn.metrics import classification_report
# 100 test cases
expected_tools = ["send_email", "read_calendar", "send_email", ...]
actual_tools = ["draft_email","read_calendar", "send_email", ...]
print(classification_report(expected_tools, actual_tools))
# precision recall f1-score
# read_calendar 0.95 0.98 0.96
# send_email 0.85 0.70 0.77 ← often confused with draft_email
# draft_email 0.60 0.90 0.72해석: send_email의 recall이 0.70이면 30% 케이스에서 send 대신 draft를 부른다는 뜻입니다. prompt에 "draft가 아니라 send를 사용하세요" 같은 예시 추가 필요.
Trajectory Efficiency — 단계 수 측정

같은 작업을 4단계로 끝낸 agent와 12단계 만에 끝낸 agent는 다릅니다. 12단계는 토큰 비용 3배, latency 3배, 실패 위험 3배입니다.
# agent_eval/efficiency.py
def trajectory_metrics(agent_run: dict, expected_steps: int) -> dict:
actual_steps = len(agent_run["steps"])
return {
"step_count": actual_steps,
"step_overhead": actual_steps / expected_steps, # 1.0 = optimal
"total_latency_s": sum(s["latency_s"] for s in agent_run["steps"]),
"total_tokens": sum(s["tokens"] for s in agent_run["steps"]),
"tool_calls": sum(1 for s in agent_run["steps"] if "tool" in s),
}
overheads = [trajectory_metrics(r, 4)["step_overhead"] for r in runs]
print(f"avg step overhead: {sum(overheads)/len(overheads):.2f}")
# avg step overhead: 1.8 ← agent uses ~2x more steps than needed경험적 기준: step overhead가 2.0을 넘으면 prompt 또는 tool 설계 재검토.
Recovery 평가 — 실패에서 살아나는가
Production agent는 tool 실패에 부딪힙니다 (API rate limit, network error 등). Agent가 재시도하거나 다른 경로를 찾는지 봅니다.
# agent_eval/recovery.py
def evaluate_recovery(agent_run: dict) -> str:
steps = agent_run["steps"]
for i, s in enumerate(steps):
if s.get("tool_result", {}).get("error"):
if i + 1 >= len(steps):
return "GAVE_UP"
next_step = steps[i + 1]
if next_step.get("tool") == s["tool"]:
return "RETRIED"
if "tool" in next_step:
return "ALTERNATIVE"
return "GAVE_UP"
return "NO_FAILURE"
# 50 runs with injected failures
results = [evaluate_recovery(r) for r in fault_injected_runs]
from collections import Counter
print(Counter(results))
# Counter({'RETRIED': 30, 'ALTERNATIVE': 12, 'GAVE_UP': 8})
# → 16% of cases the agent gave up. Reinforce recovery in the prompt.Fault injection 패턴: 평가 시 일부 tool에 가짜 에러를 주입하고 agent가 어떻게 반응하는지 측정합니다 (Ep8에서 회귀 테스트로 자동화).
종합 — Agent 평가 대시보드
위 5개를 한 번에 보면 agent 품질을 한눈에 파악할 수 있습니다.
# agent_eval/dashboard.py
import pandas as pd
results = []
for run in agent_runs: # 100 runs
results.append({
"task_success": end_to_end_success(run),
"tool_f1": step_match_score(run["steps"], expected),
"step_overhead": trajectory_metrics(run, 4)["step_overhead"],
"recovered": evaluate_recovery(run) in ("RETRIED", "ALTERNATIVE"),
})
df = pd.DataFrame(results)
print(df.describe())
# task_success tool_f1 step_overhead recovered
# mean 0.78 0.85 1.6 0.72
# std 0.41 0.18 0.7 0.45해석:
- task_success 0.78 = 22% 실패. 너무 높음.
- tool_f1 0.85 = tool 선택 보통. 가능.
- step_overhead 1.6 = 60% 더 많은 단계. 비용 문제.
- recovered 0.72 = 28% 케이스에서 실패에 굴복. 개선 필요.
이 코드에서 먼저 봐야 할 점
- 가장 먼저 end-to-end와 step-level을 나누는 부분부터 보시면 좋습니다. 최종 성공률은 헤드라인 수치이고, step-level은 실패 원인 분석 도구입니다.
- tool confusion 예제는 에이전트가 헷갈리는 도구 쌍을 바로 보여 줍니다. 프롬프트에 어떤 예시를 추가해야 할지도 여기서 드러납니다.
- recovery 평가는 실제 운영 안정성과 직결됩니다. fault injection을 넣어 보지 않으면 API 장애 시 에이전트가 그대로 멈추는지 알기 어렵습니다.
이 세 지점을 먼저 읽고 나면 세부 구현과 지표 해석이 훨씬 빨라집니다. 코드가 길어 보여도 운영 질문은 대개 여기로 다시 돌아옵니다.
어디서 자주 헷갈릴까요?
Mistake 1: 최종 답변만 평가
"이메일이 보내졌나"만 보면 agent가 5번 잘못된 이메일을 보낸 끝에 6번째에 성공해도 PASS로 나옵니다. 반드시 trajectory도 측정하세요.
Mistake 2: 정답 trajectory를 한 개만 인정
같은 작업도 여러 경로로 풀 수 있습니다. "send_email 먼저"든 "summarize 먼저"든 결과가 같으면 OK여야 합니다. expected는 set 또는 partial order로 정의하세요.
Mistake 3: Step-level만 보고 만족
각 step이 통과해도 최종 결과가 틀릴 수 있습니다 (잘못된 인자 조합). end-to-end success를 항상 함께 봅니다.
Mistake 4: Recovery 평가 안 함
Production에서는 API 실패가 빈번합니다. Recovery 평가 없이 출시하면 user-facing 에러가 폭증합니다. fault injection으로 30% 케이스에 의도적 에러 주입 후 측정.
Mistake 5: Token 비용/latency 무시
같은 task가 1000 token vs 10000 token으로 풀린다면 둘 다 PASS여도 후자는 production 부적합. step_overhead, token_count, latency_s를 dashboard에 포함.
현업에서 제가 가장 자주 보는 문제는 결과 숫자만 보고 원인 분해를 건너뛰는 습관입니다. 평가가 개선을 돕지 못하고 보고서용 숫자로만 남는 순간, 팀은 다시 감각에 의존하게 됩니다.
첫 번째 운영 체크리스트
- 최종 성공률과 trajectory 지표를 함께 기록하는가
- 도구 선택과 인자 검증을 별도 지표로 분리했는가
- step_overhead, total_tokens, total_latency를 대시보드에 올렸는가
- 실패 주입 테스트로 recovery를 정기 점검하는가
- 하나의 정답 경로만 강제하지 않고 허용 경로를 정의했는가
실무에서는 이렇게 생각한다
실무에서는 '잘 답했는가'만큼 '얼마나 비싸게 답했는가'가 중요합니다. 에이전트는 좋은 답을 낼수록 더 많이 돌기 쉬운데, 그 비용을 같이 보지 않으면 운영 단계에서 금방 발목을 잡힙니다.
또한 복구 평가는 선택이 아니라 기본값에 가깝습니다. 외부 도구를 쓰는 순간 API 실패와 타임아웃은 상수가 되기 때문입니다. 회복하지 못하는 에이전트는 작은 장애도 곧바로 사용자 오류로 바꿉니다.
다음 글의 회귀 테스트는 이런 지표를 PR 단계에서 자동으로 막는 방법으로 이어집니다. 에이전트 품질도 결국 자동화된 방어선 안에 들어와야 합니다.
정리: 에이전트 평가는 정답보다 실행 궤적을 함께 봐야 운영 판단이 가능합니다
- Agent 평가는 단일 응답 평가와 다릅니다. Task success + trajectory 둘 다 봅니다.
- 5가지 측정: task success, tool selection, tool arguments, trajectory efficiency, recovery.
- End-to-end로 큰 그림을, step-level로 실패 분석을 합니다.
- Tool selection은 classification_report로, recovery는 fault injection으로 평가합니다.
- Token cost와 latency는 정확도와 동등하게 중요한 production metric입니다.
다음 글에서는 이런 평가를 CI에 연결해 매 PR마다 회귀를 자동으로 막는 방법을 다룹니다. 에이전트든 일반 LLM 기능이든, 평가가 반복 실행되어야 비로소 운영 도구가 됩니다.
운영 체크리스트
- task success와 trajectory metrics를 함께 배포 기준으로 삼기
- tool confusion을 정기적으로 검토하기
- step overhead 2.0 이상 사례를 별도 추적하기
- fault injection으로 recovery 비율 측정하기
- 정확도와 비용을 같은 대시보드에서 함께 보기
AI Evaluation 101 시리즈
- 왜 LLM 애플리케이션을 평가해야 하는가
- 평가 데이터셋 설계하기
- 결정적 지표 — Exact Match, BLEU, ROUGE
- LLM-as-Judge — 모델로 모델을 평가하기
- Rubric 기반 채점 설계
- RAG 시스템 평가하기
- 에이전트 평가하기 — 단일 응답이 아닌 trajectory (현재 글)
- 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (예정)
- LLM A/B 테스팅 — 어느 prompt가 더 나은가 (예정)
- 운영 환경에서의 지속적 평가 (예정)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| AI Evaluation 101 : LLM A/B 테스팅 — 어느 prompt가 더 나은가 (0) | 2026.05.18 |
|---|---|
| AI Evaluation 101 : 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (0) | 2026.05.18 |
| AI Evaluation 101 : RAG 시스템 평가하기 (0) | 2026.05.18 |
| AI Evaluation 101 : Rubric 기반 채점 설계 (0) | 2026.05.18 |
| AI Evaluation 101 : LLM-as-Judge — 모델로 모델을 평가하기 (0) | 2026.05.18 |
- Total
- Today
- Yesterday
- Cloud
- AZURE
- APIDesign
- vector search
- openAI
- ai agent
- reliability
- Python
- DevOps
- Azure Functions
- softwaredesign
- Refactoring
- embeddings
- serverless
- backend
- ai safety
- LLM
- DesignPatterns
- harness
- Prompt engineering
- Tool Use
- http
- AI Evaluation
- Production
- Architecture
- rag
- langchain
- Computer Science
- Agent
- Cleancode
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |