

티스토리 뷰
LLM 팀이 평가를 갖추고도 계속 흔들리는 이유는 실행 시점이 늦기 때문인 경우가 많습니다. 큰 프롬프트 변경 뒤에만 한 번 돌리고, 모델을 바꿀 때만 잠깐 확인하고, 나머지 변경은 그냥 merge해 버리면 회귀는 결국 운영까지 흘러갑니다.
기존 소프트웨어에서 unit test가 PR 방어선인 것처럼, LLM 평가도 반복 실행되는 회귀 테스트가 되어야 합니다. 그래야 품질 저하를 사용자보다 먼저 발견할 수 있습니다.
현업에서는 여기서 Golden dataset의 크기와 임계값 정책이 중요해집니다. 너무 크면 PR이 느려지고 비싸집니다. 너무 느슨하면 회귀를 놓칩니다. 이 균형을 코드와 정책으로 굳혀야 지속됩니다.
이 글은 AI Evaluation 101 시리즈의 8번째 글입니다.
여기서는 회귀 테스트용 Golden dataset을 어떻게 만들고, 임계값을 어떻게 두고, GitHub Actions로 어떻게 매 PR 방어선에 올릴지 정리하겠습니다.
이 글에서 다룰 문제
- 평가를 한 번만 돌리는 습관이 왜 회귀를 main 브랜치까지 흘려보낼까요?
- Golden dataset은 일반 운영 평가셋과 어떤 목적 차이를 가질까요?
- any, majority, weighted 세 가지 fail policy는 어떤 운영 성격에 맞을까요?
- LLM 비결정성을 감안해 seed와 tolerance는 어떻게 설정해야 할까요?
- PR에서 회귀가 터졌을 때 재실행, diff, 의사결정은 어떤 순서로 진행해야 할까요?
왜 이 글이 중요한가
회귀 테스트가 없으면 팀은 개선과 파손을 구분하지 못합니다. 프롬프트를 고쳐 한 사례가 나아졌더라도 다른 핵심 사례가 조용히 나빠질 수 있고, 그 사실은 사용자 불만이 쌓인 뒤에야 드러납니다.
또한 LLM 기능은 코드보다 변경 빈도가 높습니다. 프롬프트, 시스템 지시문, 검색 전략, 모델 버전이 모두 자주 바뀌기 때문에, 사람이 기억으로 기준선을 지키는 방식은 오래 못 갑니다.
그래서 회귀 테스트는 편의 기능이 아니라 운영 안전장치입니다. 평가를 PR 단계로 끌어와야 품질 저하가 main으로 들어가기 전에 막힙니다.
회귀 테스트를 이해하는 가장 좋은 방법: LLM 평가를 배포 전 행사가 아니라 PR 방어선으로 옮기는 것입니다
이 주제는 개별 기법을 외우기보다 먼저 어떤 운영 문제를 풀기 위한 장치인지 붙잡아 두는 편이 이해가 빠릅니다. 회귀 테스트가 없으면 팀은 개선과 파손을 구분하지 못합니다. 프롬프트를 고쳐 한 사례가 나아졌더라도 다른 핵심 사례가 조용히 나빠질 수 있고, 그 사실은 사용자 불만이 쌓인 뒤에야 드러납니다.
좋은 평가가 있어도 수동으로 한 번 돌리고 끝나면 회귀는 결국 main 브랜치로 들어갑니다. 회귀 테스트의 목적은 품질 토론이 아니라, 어제 지킨 품질선을 오늘 PR에서 자동으로 방어하는 데 있습니다.
이 관점을 먼저 잡아 두면 뒤에 나오는 코드와 지표를 기능 설명이 아니라 운영 설계 관점에서 읽을 수 있습니다. 결국 중요한 것은 수치 이름보다, 그 수치가 어떤 의사결정을 가능하게 하느냐입니다.
핵심 개념
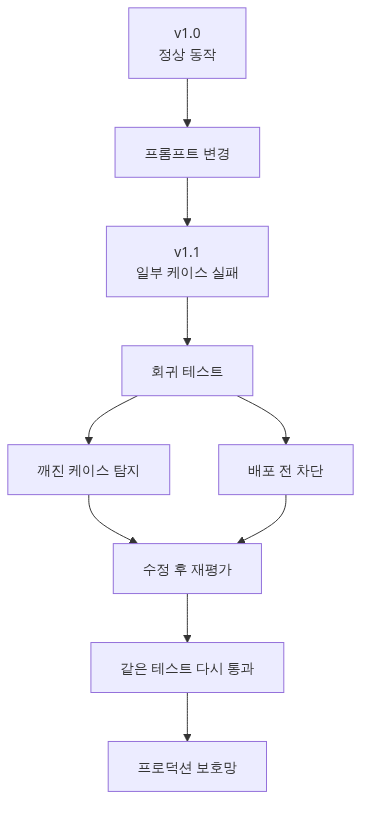
평가는 한 번이 아니라 매번 합니다

Ep1~Ep7에서 평가 방법을 다뤘습니다. 그런데 평가를 언제 실행할까요? 흔한 패턴은:
- 큰 prompt 변경 직후 한 번 돌려보기
- 새 모델로 바꿀 때 한 번 돌려보기
- 그 외에는 잊어버리기
이 방식의 문제는 회귀가 production에 도달한다는 점입니다. 어제 잘 동작하던 답변이 오늘은 품질이 떨어지는데 아무도 모릅니다. 평가는 unit test처럼 매 PR마다 자동으로 돌아야 합니다.
이번 글에서는 다음을 다룹니다.
- Golden dataset 설계
- 임계값(threshold) 정의와 fail policy
- GitHub Actions에 통합
- 회귀 발견 시 처리 절차
Golden Dataset — 변하지 않는 핵심 케이스

Regression dataset은 production용 평가 데이터셋(Ep2)과 다릅니다.
| 구분 | Production eval (Ep2) | Regression (Ep8) |
|---|---|---|
| 크기 | 100~1000건 | 20~50건 |
| 변경 빈도 | 매월 추가 | 거의 안 바꿈 |
| 목적 | 전반적 품질 | 핵심 기능 회귀 방지 |
| 비용 | 한 번에 $10~100 | 매 PR마다 $0.5~5 |
Golden dataset 선정 기준:
- 사용 빈도 top 20% — 가장 많이 들어오는 질문 패턴
- 과거 회귀가 있었던 케이스 — 한 번 망가진 적 있는 입력
- edge case — 빈 입력, 매우 긴 입력, multilingual, 모호한 의도
# regression/golden_dataset.py
import json
GOLDEN = [
# Top usage cases
{"id": "freq-001", "input": "today's weather", "expected_intent": "weather_query"},
{"id": "freq-002", "input": "change my password", "expected_intent": "account_password"},
# Past regressions (with commit reference)
{"id": "reg-001", "input": "where is my order?",
"expected_contains": ["order", "status"],
"note": "v1.2 returned 'item' instead of 'order' (PR #234)"},
# Edge cases
{"id": "edge-001", "input": "", "expected_behavior": "ask_clarification"},
{"id": "edge-002", "input": "asdfgh", "expected_behavior": "ask_clarification"},
{"id": "edge-003", "input": "Hi! I'm John. Actually I'm Mike. No wait, Sarah.",
"expected_behavior": "ask_clarification"},
]
with open("regression/golden.jsonl", "w") as f:
for item in GOLDEN:
f.write(json.dumps(item, ensure_ascii=False) + "\n")원칙: Golden은 20~50건만 유지합니다. 너무 많으면 매 PR이 느려지고 비싸집니다.
임계값과 Fail Policy

평가 점수가 나왔다고 끝이 아닙니다. 어떤 점수가 fail인지 정해야 합니다.
# regression/thresholds.py
THRESHOLDS = {
"exact_match": 0.80, # Ep3
"bleu": 0.40,
"judge_score": 4.0, # Ep4 on 1-5 scale
"faithfulness": 0.85, # Ep6 RAG
"task_success": 0.90, # Ep7 agent
}
FAIL_POLICY = "any" # "any" | "majority" | "weighted"3가지 fail policy를 비교합니다.
| Policy | 의미 | 장점 | 단점 |
|---|---|---|---|
any |
메트릭 1개라도 임계값 미만 → fail | 안전 | false positive 많음 |
majority |
과반수 메트릭이 미만 → fail | 균형 | 한 메트릭 폭락을 놓침 |
weighted |
가중 평균이 미만 → fail | 도메인 맞춤 | 가중치 조정 필요 |
경험적 권장: 처음에는 any로 시작. False positive가 많으면 weighted로 전환.
CI 통합 — GitHub Actions

매 PR마다 평가를 자동 실행하는 GitHub Actions workflow:
# .github/workflows/eval.yml
name: Regression Eval
on:
pull_request:
paths:
- "src/**"
- "prompts/**"
- "regression/**"
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- run: pip install -r requirements.txt
- name: Run regression eval
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
python -m regression.run > eval_report.json
- name: Check thresholds
run: |
python -m regression.check_thresholds eval_report.json
- name: Upload report
if: always()
uses: actions/upload-artifact@v4
with:
name: eval-report
path: eval_report.json# regression/check_thresholds.py
import json, sys
from .thresholds import THRESHOLDS, FAIL_POLICY
def check(report_path: str) -> int:
with open(report_path) as f:
report = json.load(f)
failures = []
for metric, threshold in THRESHOLDS.items():
if metric not in report:
continue
score = report[metric]
if score < threshold:
failures.append(f"{metric}: {score:.3f} < {threshold}")
if FAIL_POLICY == "any" and failures:
print("FAIL — threshold violations:")
for f in failures:
print(f" - {f}")
return 1
print("PASS — all metrics above threshold")
return 0
if __name__ == "__main__":
sys.exit(check(sys.argv[1]))핵심: PR이 평가를 fail하면 merge가 막힙니다. 회귀가 main 브랜치에 도달하기 전에 잡힙니다.
비결정성 처리 — Seed와 Tolerance
LLM 평가는 결정론적이지 않습니다. 같은 PR을 두 번 돌리면 점수가 0.02 정도 다를 수 있습니다. 두 가지 대응:
대응 1: Temperature와 seed 고정
response = client.chat.completions.create(
model="gpt-4o",
messages=[...],
temperature=0,
seed=42, # OpenAI seed parameter
)seed는 best-effort라 100% 보장되지 않지만 변동을 크게 줄입니다.
대응 2: 임계값에 tolerance 추가
# regression/thresholds.py
THRESHOLDS_WITH_TOLERANCE = {
"exact_match": (0.80, 0.02), # pass at >= 0.78 (0.02 tolerance)
"judge_score": (4.0, 0.1),
"faithfulness": (0.85, 0.02),
}
def check_with_tolerance(metric: str, score: float) -> bool:
threshold, tol = THRESHOLDS_WITH_TOLERANCE[metric]
return score >= (threshold - tol)원칙: tolerance는 이전 main 브랜치 점수의 표준편차의 2배 정도로 설정. 지나치게 크면 회귀를 놓치고, 작으면 false positive.
회귀 발견 시 처리 절차
PR이 fail했을 때 다음 절차를 따릅니다.
- 재실행: 비결정성 때문일 수 있음. 한 번 더 돌려봅니다.
- 개별 케이스 확인: 어느 입력이 회귀했는지 봅니다.
# main 기준선과 비교해 회귀 케이스를 찾습니다. def diff_against_main(current: dict, main_baseline: dict) -> list[str]: regressed = [] for case_id in current: if current[case_id]["score"] < main_baseline[case_id]["score"] - 0.1: regressed.append(case_id) return regressed - 두 가지 결정:
- 회귀가 의도된 것: 임계값을 새 baseline으로 업데이트하고 PR description에 명시.
- 버그: 코드/prompt 수정 후 재시도.
이 코드에서 먼저 봐야 할 점
- Production eval과 Golden regression set을 비교한 표부터 보시면 두 데이터셋의 역할 차이가 분명해집니다.
THRESHOLDS와FAIL_POLICY예제는 점수만 보는 것이 아니라 '무엇을 fail로 볼지'를 코드로 못 박는 부분입니다.- GitHub Actions 워크플로는 평가가 팀 문화가 아니라 merge 조건이 되는 순간을 보여 줍니다.
이 세 지점을 먼저 읽고 나면 세부 구현과 지표 해석이 훨씬 빨라집니다. 코드가 길어 보여도 운영 질문은 대개 여기로 다시 돌아옵니다.
어디서 자주 헷갈릴까요?
Mistake 1: Golden dataset이 너무 큼
500건의 golden을 매 PR마다 돌리면 시간 30분, 비용 $20
50. **20
50건으로 제한**하고 production용 큰 dataset은 nightly로.
Mistake 2: 임계값을 너무 높게 설정
"exact_match >= 0.95" 같은 임계값은 LLM의 자연스러운 변동에 항상 fail합니다. 현재 main 점수의 -2σ를 임계값으로 시작하세요.
Mistake 3: Threshold 한 번 정하고 안 봄
모델, prompt, 데이터가 발전하면 baseline도 올라가야 합니다. 분기마다 임계값을 재검토하고 너무 느슨해진 것은 올리세요.
Mistake 4: 평가 코드 자체를 테스트하지 않음
평가 함수에 버그가 있으면 모든 점수가 거짓입니다. 평가 함수에 unit test를 작성하세요 (known input → expected score).
Mistake 5: 비용 모니터링 안 함
매 PR마다 $5씩, 한 달 100 PR이면 $500입니다. CI 비용을 매주 측정하고 10% 이상 증가하면 sampling 도입.
현업에서 제가 가장 자주 보는 문제는 결과 숫자만 보고 원인 분해를 건너뛰는 습관입니다. 평가가 개선을 돕지 못하고 보고서용 숫자로만 남는 순간, 팀은 다시 감각에 의존하게 됩니다.
첫 번째 운영 체크리스트
- Golden dataset을 20~50건 핵심 사례로 유지하는가
- 임계값과 fail policy를 코드로 관리하는가
- PR마다 자동 평가가 돌고 merge를 차단하는가
- 비결정성 허용 오차를 최근 분산 기반으로 정하는가
- 평가 실패 시 재실행과 diff 분석 절차가 정해져 있는가
실무에서는 이렇게 생각한다
실무에서는 Golden dataset을 크게 만드는 것보다 날카롭게 만드는 편이 더 중요합니다. 자주 쓰는 사례, 과거 회귀 사례, 치명적 엣지 케이스만 넣어도 방어력은 크게 올라갑니다.
또한 threshold는 한 번 정하면 끝나는 숫자가 아닙니다. 모델과 프롬프트가 개선되면 기준선도 함께 올라가야 하고, 반대로 비결정성 때문에 너무 빡빡하면 팀이 경보를 무시하게 됩니다.
다음 글의 A/B 테스트는 이 회귀 방어선 위에서 더 나은 변형을 선택하는 단계입니다. 먼저 뒤로 가지 않게 막고, 그다음 앞으로 나아가야 합니다.
정리: 회귀 테스트는 LLM 품질을 PR 수준의 기본 안전장치로 바꾸는 과정입니다
- 평가는 unit test처럼 매 PR마다 자동으로 돌아야 합니다. 그래야 회귀가 production에 도달하지 않습니다.
- Golden dataset은 20~50건의 핵심 + edge + 과거 회귀 케이스로 구성합니다.
- Fail policy 3가지(any/majority/weighted)와 tolerance를 통해 false positive를 통제합니다.
- GitHub Actions으로 PR마다 자동 실행하고, 임계값 미달 시 merge 차단.
- 회귀 발견 시 재실행 → diff → 의도된 변경인지 버그인지 결정.
이제 방어선이 생겼다면, 다음 글에서는 두 모델이나 두 프롬프트 가운데 무엇이 더 나은지를 통계적으로 비교하는 A/B 테스트로 넘어갑니다.
운영 체크리스트
- Golden dataset을 작고 날카롭게 유지하기
- 임계값 미달 시 자동 실패하도록 CI에 연결하기
- seed와 tolerance를 함께 관리하기
- 실패 사례를 diff로 바로 읽을 수 있게 만들기
- 분기마다 threshold를 재검토하기
AI Evaluation 101 시리즈
- 왜 LLM 애플리케이션을 평가해야 하는가
- 평가 데이터셋 설계하기
- 결정적 지표 — Exact Match, BLEU, ROUGE
- LLM-as-Judge — 모델로 모델을 평가하기
- Rubric 기반 채점 설계
- RAG 시스템 평가하기
- 에이전트 평가하기 — 단일 응답이 아닌 trajectory
- 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (현재 글)
- LLM A/B 테스팅 — 어느 prompt가 더 나은가 (예정)
- 운영 환경에서의 지속적 평가 (예정)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| AI Evaluation 101 : 운영 환경에서의 지속적 평가 (0) | 2026.05.18 |
|---|---|
| AI Evaluation 101 : LLM A/B 테스팅 — 어느 prompt가 더 나은가 (0) | 2026.05.18 |
| AI Evaluation 101 : 에이전트 평가하기 — 단일 응답이 아닌 trajectory (0) | 2026.05.18 |
| AI Evaluation 101 : RAG 시스템 평가하기 (0) | 2026.05.18 |
| AI Evaluation 101 : Rubric 기반 채점 설계 (0) | 2026.05.18 |
- Total
- Today
- Yesterday
- rag
- ai agent
- Computer Science
- Production
- Python
- ai safety
- Prompt engineering
- http
- backend
- APIDesign
- AI Evaluation
- harness
- Cleancode
- Azure Functions
- LLM
- embeddings
- softwaredesign
- AZURE
- reliability
- DesignPatterns
- DevOps
- openAI
- langchain
- vector search
- Agent
- serverless
- Architecture
- Tool Use
- Cloud
- Refactoring
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |