

티스토리 뷰
배포 전 평가가 통과했다고 해서 서비스가 안전해지는 것은 아닙니다. 운영에서는 사용자가 예상 밖 질문을 던지고, 공급사 모델이 조용히 바뀌고, 유입 채널이 달라지면서 입력 분포도 계속 움직입니다. 평가가 배포 시점에서 멈추면 팀은 실제 품질 저하를 너무 늦게 발견합니다.
특히 LLM 서비스는 온라인 신호가 풍부합니다. thumbs up/down, 재질문율, 응답 지연, 비용, 에스컬레이션 여부가 모두 품질과 연결됩니다. 이 신호를 수집하지 않으면 judge 점수만으로는 운영 상태를 충분히 읽기 어렵습니다.
현업에서 저는 운영 실패를 다음 회귀셋으로 환류시키는 팀이 가장 빠르게 강해지는 것을 봤습니다. 운영에서 배운 실패를 다시 배포 방어선에 넣는 순간, 같은 사고가 반복될 확률이 급격히 줄어듭니다.
이 글은 AI Evaluation 101 시리즈의 마지막 글입니다.
여기서는 운영 트레이스 샘플링, 온라인 지표, 드리프트 감지, shadow mode, 비용 경보, 실패 환류까지 연결해서 평가를 지속적 운영 루프로 만드는 방법을 정리하겠습니다.
이 글에서 다룰 문제
- 배포 전 평가만으로는 왜 운영 품질을 끝까지 보장할 수 없을까요?
- 운영 트레이스를 샘플링할 때 균등, 계층, 실패 편향 전략을 왜 함께 써야 할까요?
- thumbs, 재질문율, 지연, 비용 같은 온라인 지표는 judge 평가와 어떻게 역할을 나눌까요?
- 입력 분포와 출력 스타일이 바뀌는 드리프트를 어떻게 감지할 수 있을까요?
- 운영 실패를 회귀셋으로 되돌리는 루프가 왜 장기적으로 가장 큰 자산이 될까요?
왜 이 글이 중요한가
운영 평가는 배포 후 품질을 추적하는 유일한 현실적 방법입니다. 오프라인 데이터셋이 아무리 좋아도 실제 사용자 분포가 달라지면 기준선은 금방 낡습니다.
또한 운영에서는 비용도 품질 지표입니다. judge 호출이 serving 비용을 잠식하기 시작하면 평가 체계 자체가 지속 가능하지 않습니다. 그래서 샘플링, 경보 임계값, 비용 비율 관리가 모두 필요합니다.
마지막으로 운영 실패를 다시 회귀셋으로 넣는 순간 평가 체계가 닫힌 루프가 됩니다. 이 루프가 있어야 팀이 같은 실패를 두 번 비싼 값으로 배우지 않게 됩니다.
운영 평가를 이해하는 가장 좋은 방법: 배포 전 검사를 운영 루프로 닫는 것입니다
이 주제는 개별 기법을 외우기보다 먼저 어떤 운영 문제를 풀기 위한 장치인지 붙잡아 두는 편이 이해가 빠릅니다. 운영 평가는 배포 후 품질을 추적하는 유일한 현실적 방법입니다. 오프라인 데이터셋이 아무리 좋아도 실제 사용자 분포가 달라지면 기준선은 금방 낡습니다.
배포 전 평가는 통제된 리허설입니다. 운영 평가는 실제 사용자, 실제 분포 변화, 실제 비용 제약 속에서 품질을 계속 감시하고, 실패를 다음 배포 방어선으로 환류시키는 루프입니다.
이 관점을 먼저 잡아 두면 뒤에 나오는 코드와 지표를 기능 설명이 아니라 운영 설계 관점에서 읽을 수 있습니다. 결국 중요한 것은 수치 이름보다, 그 수치가 어떤 의사결정을 가능하게 하느냐입니다.
핵심 개념

배포 후가 진짜 시작입니다

배포 전 평가는 통제된 환경에서의 시뮬레이션입니다. 진짜 사용자는 예상치 못한 입력을 던지고, 모델 공급사는 조용히 모델을 업데이트하고, 데이터 분포는 시간에 따라 흘러갑니다. 운영 환경에서 평가가 멈추면 품질 저하를 누구도 알아채지 못합니다.
이 글에서는 다음을 다룹니다.
- Production trace 샘플링 전략
- Online metric 수집 (피드백, 지연시간, 재질문율)
- Drift detection으로 분포 변화 감지
- Shadow mode로 신규 모델 안전 검증
- Baseline 대비 alert threshold 설계
- 평가 자체의 비용 모니터링
이전 9개 에피소드를 운영 단계로 연결하는 마지막 글입니다.
섹션 1 — Production Trace 샘플링

운영 트래픽 전체를 평가하면 비용이 폭발합니다. 일부만 샘플링하되, 편향되지 않게 추출해야 합니다.
균등 샘플링 (uniform sampling)
import random
def uniform_sample(traces: list[dict], rate: float = 0.01) -> list[dict]:
"""Pick `rate` fraction of traces uniformly."""
return [t for t in traces if random.random() < rate]
# 1% of 100k daily requests = 1,000 traces for evaluation
sampled = uniform_sample(today_traces, rate=0.01)가장 단순하지만, 희소한 케이스 (예: 의료 질문, 법률 질문)는 거의 잡히지 않습니다.
계층 샘플링 (stratified sampling)
카테고리별로 최소 N건을 보장합니다.
from collections import defaultdict
def stratified_sample(traces: list[dict], per_category: int = 50) -> list[dict]:
buckets = defaultdict(list)
for t in traces:
buckets[t["category"]].append(t)
sampled = []
for cat, items in buckets.items():
n = min(per_category, len(items))
sampled.extend(random.sample(items, n))
return sampled이렇게 하면 희소 카테고리의 품질도 추적할 수 있습니다.
실패 우선 샘플링
낮은 confidence, 짧은 응답, 사용자가 thumbs-down을 누른 trace를 우선 샘플링합니다. 문제가 있을 가능성이 높은 trace에 평가 예산을 집중하는 전략입니다.
def failure_biased_sample(traces, rate_pass=0.005, rate_fail=0.5):
sampled = []
for t in traces:
threshold = rate_fail if t.get("user_feedback") == "down" else rate_pass
if random.random() < threshold:
sampled.append(t)
return sampled섹션 2 — Online Metric 수집
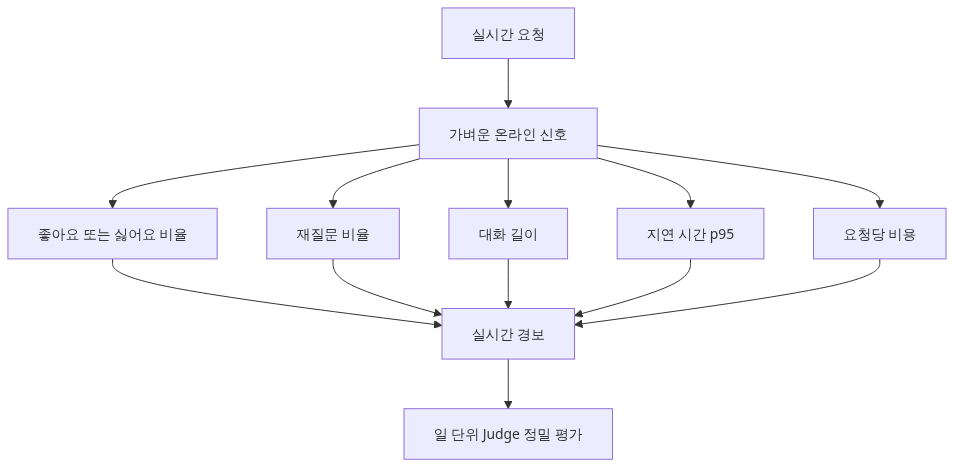
배포 후에는 LLM-as-judge 같은 무거운 평가뿐 아니라, 가벼운 online signal을 실시간으로 모아야 합니다.
| Metric | 의미 | 측정 방법 |
|---|---|---|
| Thumbs up/down rate | 사용자 직접 피드백 | UI 버튼 클릭 로깅 |
| Re-ask rate | 같은 사용자가 5분 내 같은 질문 재시도 | session id + query similarity |
| Conversation length | 한 task를 끝내는 데 걸린 turn 수 | session log 집계 |
| Latency p50 / p95 | 응답 속도 | 요청별 timestamp |
| Cost per request | 호출당 토큰 비용 | usage 필드 합산 |
from dataclasses import dataclass
from datetime import datetime
@dataclass
class TraceMetric:
trace_id: str
timestamp: datetime
latency_ms: int
input_tokens: int
output_tokens: int
user_feedback: str | None # "up", "down", None
re_asked: bool
def daily_summary(metrics: list[TraceMetric]) -> dict:
n = len(metrics)
return {
"total": n,
"thumbs_down_rate": sum(1 for m in metrics if m.user_feedback == "down") / n,
"re_ask_rate": sum(1 for m in metrics if m.re_asked) / n,
"p95_latency_ms": sorted(m.latency_ms for m in metrics)[int(n * 0.95)],
"avg_cost_usd": sum(m.input_tokens * 0.000005 + m.output_tokens * 0.000015 for m in metrics) / n,
}Online metric은 early warning system 역할을 합니다. judge 평가는 비싸서 일 단위로 돌리지만, online metric은 분 단위로 추적합니다.
섹션 3 — Drift Detection

입력 분포가 바뀌면 (사용자 질문 패턴 변화, 신규 사용자 유입), 기존 평가 데이터셋의 결과가 운영 품질을 더 이상 반영하지 못합니다.
입력 분포 비교 — KL divergence
import math
from collections import Counter
def kl_divergence(p: dict[str, float], q: dict[str, float], eps: float = 1e-9) -> float:
"""KL(P || Q): how much P diverges from Q."""
total = 0.0
for key, p_val in p.items():
q_val = q.get(key, eps)
total += p_val * math.log((p_val + eps) / (q_val + eps))
return total
def category_distribution(traces: list[dict]) -> dict[str, float]:
counts = Counter(t["category"] for t in traces)
n = sum(counts.values())
return {k: v / n for k, v in counts.items()}
baseline = category_distribution(traces_last_week)
current = category_distribution(traces_today)
drift = kl_divergence(current, baseline)
if drift > 0.1:
alert("Input distribution drift detected")KL divergence 0.1 이상이면 분포가 의미 있게 달라졌다고 판단합니다. 임계값은 baseline 변동성을 30일 정도 측정해서 잡아야 합니다.
Output drift
같은 입력 카테고리에 대해 응답 길이, 응답 거절율 (refusal rate), tone이 갑자기 달라지면 모델 공급사가 조용히 업데이트했을 가능성이 있습니다.
def refusal_rate(traces: list[dict]) -> float:
refusals = sum(1 for t in traces if "I cannot" in t["output"] or "I'm sorry" in t["output"])
return refusals / len(traces)모델 공급사의 silent update는 모니터링하지 않으면 알 수 없습니다.
섹션 4 — Shadow Mode와 Canary
신규 모델이나 새 프롬프트를 운영에 투입하기 전, shadow mode로 기존 모델과 병렬로 호출해서 응답을 비교합니다.
async def shadow_call(input_text: str):
"""Serve from the primary model, log a shadow call to the candidate."""
primary = await call_model("gpt-4o", input_text)
asyncio.create_task(log_shadow(input_text, primary))
return primary
async def log_shadow(input_text: str, primary_output: str):
shadow = await call_model("gpt-4o-mini", input_text)
await db.insert_shadow_comparison({
"input": input_text,
"primary": primary_output,
"shadow": shadow,
"timestamp": datetime.utcnow(),
})수집된 shadow 응답은 Ep4의 LLM-as-judge로 pairwise 비교하면 신규 모델의 win rate를 사용자 영향 없이 측정할 수 있습니다. Canary는 한 단계 더 나아가 트래픽의 5%를 신규 모델로 보내고 online metric을 비교합니다.
섹션 5 — Alert Threshold 설계
고정 임계값 (thumbs_down_rate > 5%)은 위험합니다. 카테고리별로 baseline이 다르고, 요일/시간대 패턴도 있습니다.
Baseline 대비 상대 임계값
def relative_alert(current: float, baseline_mean: float, baseline_std: float, k: float = 3.0) -> bool:
"""Alert when current value is more than k std from baseline mean."""
return abs(current - baseline_mean) > k * baseline_std
# Learn baseline from past 30 days
baseline_mean = 0.03
baseline_std = 0.008
if relative_alert(today_rate, baseline_mean, baseline_std):
page_oncall("thumbs_down_rate anomaly")3-sigma 기준은 정상 분포 가정에서 0.27% 확률로만 발생하므로 false positive를 줄여 줍니다.
Alert fatigue 방지
같은 alert이 1시간 내 반복되면 묶어서 한 번만 보냅니다. severity 분리 (warning vs page)도 필수입니다. on-call이 모든 alert에 깨어나면 결국 모든 alert을 무시하게 됩니다.
섹션 6 — 평가 비용 모니터링
LLM-as-judge는 호출당 비용이 발생합니다. 모니터링하지 않으면 평가 비용이 운영 비용을 추월합니다.
@dataclass
class JudgeUsage:
date: str
judge_calls: int
judge_cost_usd: float
serving_cost_usd: float
def cost_ratio_alert(usage: JudgeUsage, max_ratio: float = 0.1):
ratio = usage.judge_cost_usd / usage.serving_cost_usd
if ratio > max_ratio:
alert(f"Judge cost is {ratio:.1%} of serving cost — exceeds {max_ratio:.0%} budget")평가 비용이 운영 비용의 10%를 넘으면 sampling rate를 낮추거나 더 작은 judge 모델로 교체해야 합니다.
섹션 7 — Production Failure를 다시 평가 데이터셋으로
운영에서 발견된 실패 케이스 (low rating, re-ask, escalation)는 가장 가치 있는 평가 데이터입니다. Ep8의 regression dataset에 추가해서 다음 배포 전에 자동으로 검증되게 해야 합니다.
def harvest_failures_to_regression_set(failed_traces: list[dict], regression_path: str):
new_cases = [
{
"input": t["input"],
"expected": t.get("ground_truth") or "TBD - human label needed",
"category": t["category"],
"source": "production_failure",
"harvested_at": datetime.utcnow().isoformat(),
}
for t in failed_traces
]
with open(regression_path, "a") as f:
for case in new_cases:
f.write(json.dumps(case) + "\n")이 사이클이 닫히면 운영 → 평가 데이터셋 → 다음 배포 → 운영의 순환이 자동화됩니다. 모든 실패가 시스템을 학습시키는 자산이 됩니다.
이 코드에서 먼저 봐야 할 점
- 세 가지 샘플링 전략을 먼저 보시면 평가 예산을 어디에 써야 하는지 감이 잡힙니다. 전체를 다 볼 수 없기 때문에 무엇을 더 자주 볼지 결정해야 합니다.
- 온라인 지표 테이블은 judge 평가와 실시간 신호가 어떻게 역할을 나누는지 보여 줍니다. 분 단위 신호와 일 단위 judge를 섞어야 운영이 안정됩니다.
- 마지막 failure harvesting 코드는 이 시리즈의 닫는 고리입니다. 운영 실패를 다음 배포 방어선으로 되돌리는 순간 평가 시스템이 진짜 자가 학습 루프를 갖습니다.
이 세 지점을 먼저 읽고 나면 세부 구현과 지표 해석이 훨씬 빨라집니다. 코드가 길어 보여도 운영 질문은 대개 여기로 다시 돌아옵니다.
어디서 자주 헷갈릴까요?
- 균등 샘플링만 사용 — 희소 카테고리 품질이 보이지 않습니다. Stratified + failure-biased를 조합하세요.
- 고정 임계값 alert — 카테고리/시간대 패턴을 무시하면 false positive로 신뢰를 잃습니다.
- Online metric 없이 judge에만 의존 — judge는 분 단위 모니터링이 불가능합니다. thumbs/re-ask 같은 가벼운 신호와 결합해야 합니다.
- Shadow mode 결과를 분석하지 않음 — 로깅만 하고 비교를 안 하면 무용지물입니다. 주간 win rate 리뷰를 정례화하세요.
- 평가 비용을 추적하지 않음 — judge 호출 비용이 어느 순간 운영 비용을 넘는 일이 흔합니다. 비용도 metric입니다.
현업에서 제가 가장 자주 보는 문제는 결과 숫자만 보고 원인 분해를 건너뛰는 습관입니다. 평가가 개선을 돕지 못하고 보고서용 숫자로만 남는 순간, 팀은 다시 감각에 의존하게 됩니다.
첫 번째 운영 체크리스트
- 운영 샘플링을 균등, 계층, 실패 편향으로 나눠 설계했는가
- thumbs, 재질문율, latency, cost를 온라인 지표로 수집하는가
- 입력 분포와 출력 드리프트 경보가 있는가
- shadow mode와 canary 절차를 배포 표준으로 두는가
- 운영 실패를 회귀셋으로 환류하는 자동화가 있는가
실무에서는 이렇게 생각한다
실무에서는 운영 평가가 모델 팀만의 일이 되면 오래 못 갑니다. 제품, 지원, 온콜 팀이 함께 보는 온라인 지표가 있어야 품질 변화가 조직의 공통 신호가 됩니다.
또한 고정 임계값보다 기준선 대비 이상 탐지가 더 실용적입니다. 카테고리와 시간대마다 기본 수준이 다른데, 단일 숫자로만 경보를 걸면 금방 경보 피로가 쌓입니다.
이 시리즈를 마무리하는 핵심은 평가를 한 번의 체크리스트가 아니라 루프로 보는 것입니다. 데이터셋, 지표, 회귀 테스트, A/B 실험, 운영 신호가 연결되어야 팀이 실제로 더 강해집니다.
정리: 운영 평가는 배포 전 평가를 실제 서비스 루프로 완성하는 마지막 단계입니다
- Production trace 샘플링은 균등 + stratified + failure-biased를 조합합니다.
- Online metric (thumbs, re-ask, latency, cost)은 judge 평가의 early warning system입니다.
- Drift detection은 입력/출력 분포 변화를 KL divergence와 refusal rate로 추적합니다.
- Shadow mode와 canary는 신규 모델을 사용자 영향 없이 검증하는 표준 패턴입니다.
- 상대 임계값 alert (baseline ± 3σ)이 고정 임계값보다 안정적입니다.
- Production failure를 regression dataset으로 환류해서 평가-배포 순환을 닫아야 합니다.
평가는 배포 전 한 번이 아니라 운영 중 계속되는 활동입니다. AI Evaluation 101 시리즈를 마칩니다.
이 글로 AI Evaluation 101 시리즈를 마칩니다. 이제 중요한 것은 각 글의 기법을 따로 기억하는 것이 아니라, 평가 데이터셋부터 운영 환류까지 하나의 연속된 시스템으로 연결해 두는 일입니다.
운영 체크리스트
- 운영 샘플링 전략을 한 가지로 단순화하지 않기
- judge 평가와 온라인 지표를 함께 운영하기
- 드리프트와 비용 경보를 별도 관리하기
- shadow 결과를 정기적으로 실제 비교 분석하기
- 운영 실패를 다음 회귀셋에 즉시 추가하기
AI Evaluation 101 시리즈
- 왜 LLM 애플리케이션을 평가해야 하는가
- 평가 데이터셋 설계하기
- 결정적 지표 — Exact Match, BLEU, ROUGE
- LLM-as-Judge — 모델로 모델을 평가하기
- Rubric 기반 채점 설계
- RAG 시스템 평가하기
- 에이전트 평가하기 — 단일 응답이 아닌 trajectory
- 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게
- LLM A/B 테스팅 — 어느 prompt가 더 나은가
- 운영 환경에서의 지속적 평가 (현재 글)
참고 자료
공식 문서
'AI·LLM' 카테고리의 다른 글
| Korean AI Stack 101 (2/6) : KoSimCSE로 문장 유사도 구현하기 (0) | 2026.05.19 |
|---|---|
| Korean AI Stack 101 (1/6): 한국어 임베딩 모델 비교 — KoSimCSE, BGE-M3, Solar (0) | 2026.05.19 |
| AI Evaluation 101 : LLM A/B 테스팅 — 어느 prompt가 더 나은가 (0) | 2026.05.18 |
| AI Evaluation 101 : 회귀 테스트 — 어제 잘 되던 게 오늘 망가지지 않게 (0) | 2026.05.18 |
| AI Evaluation 101 : 에이전트 평가하기 — 단일 응답이 아닌 trajectory (0) | 2026.05.18 |
- Total
- Today
- Yesterday
- DesignPatterns
- Python
- langchain
- Prompt engineering
- http
- LLM
- Architecture
- Refactoring
- ai agent
- DevOps
- Agent
- ai safety
- vector search
- AI Evaluation
- AZURE
- embeddings
- softwaredesign
- webdevelopment
- reliability
- Cloud
- Computer Science
- harness
- Production
- rag
- Azure Functions
- Cleancode
- backend
- APIDesign
- openAI
- Tool Use
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |